Category | DevOps
Last Updated On 13/10/2025

Your system might be running, but is it truly reliable? This is where Site Reliability Engineering Principles come into play. SRE roles and responsibilities are all about applying software engineering approaches to IT operations, ensuring systems are scalable, reliable, and performant. By following these principles, organizations can reduce downtime, improve user experience, and proactively manage operational risks.
Demand for skilled SRE engineers is growing rapidly as businesses increasingly depend on high-availability applications. Organizations implementing SRE practices report up to a 50% reduction in unplanned downtime, along with significant increases in deployment frequency and overall service reliability, according to insights from the Google SRE Workbook and industry surveys, proving that SRE principles deliver measurable results.
This guide breaks down SRE roles and responsibilities, key principles, essential skills, and the tools that make SRE a game-changing discipline for tech organizations.
At its core, Site Reliability Engineering is the discipline that brings software engineering practices into IT operations. SRE roles and responsibilities focus on building automated solutions, monitoring systems, and designing scalable infrastructure to maintain reliability even under high demand.
SRE bridges the gap between development and operations, ensuring that new features don’t compromise stability.
For a deeper dive, check out our comprehensive blog on SRE Fundamentals.
These Site Reliability Engineering Principles create a culture where reliability is integral to every decision, not just an afterthought.
Practitioner Tip: When managing error budgets, ensure that both development and operations teams understand the trade-offs. Many organizations achieve faster release cycles without compromising reliability by actively tracking SLIs/SLOs and reviewing error budgets weekly.
A skilled SRE engineer wears many hats of SRE Responsibilities. Understanding SRE roles and responsibilities is essential for building reliable systems:
By understanding these SRE roles and responsibilities, teams can clearly define accountability and focus on high-impact reliability initiatives.
Case Example: A major e-commerce platform reduced customer-facing downtime by 40% within six months by implementing blameless postmortems and automating repetitive operational tasks, demonstrating how SRE principles translate into tangible business outcomes.
To thrive as an SRE, mastering both technical and soft skills is essential. These shape how effectively you execute SRE engineer roles and responsibilities.
Tools simplify and strengthen SRE practices. They help execute SRE responsibilities efficiently:
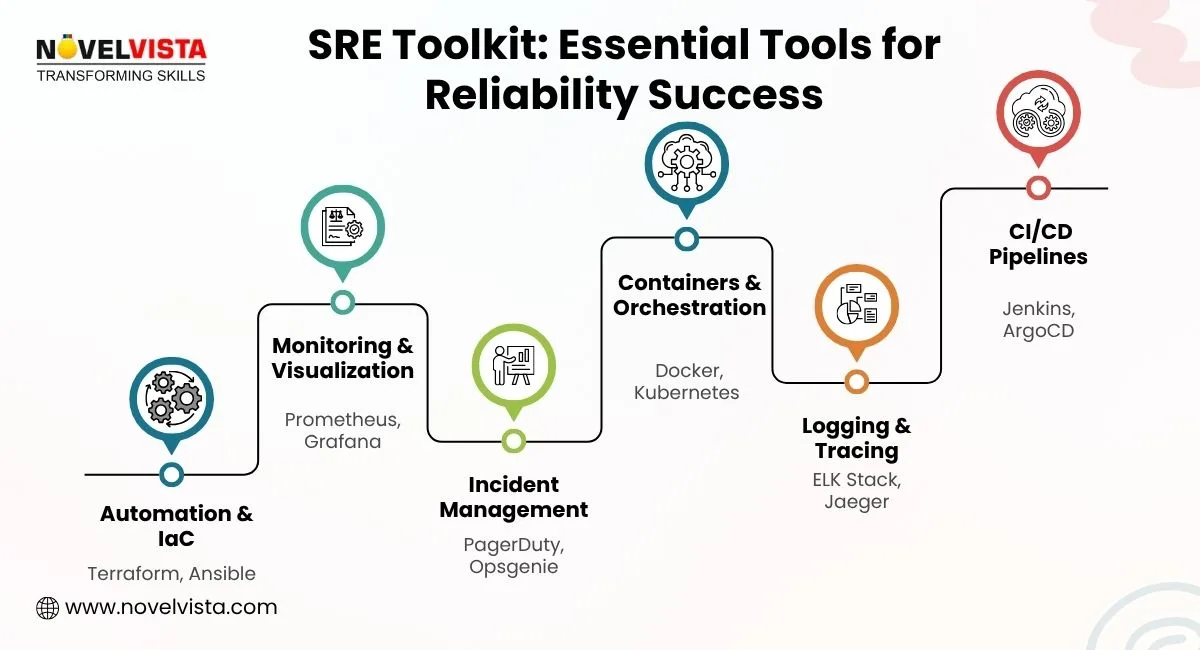
Expert Insight: Tools like Prometheus and Grafana are most effective when configured with team-specific dashboards that align metrics to business-critical SLIs. In top-tier organizations, these dashboards inform daily operations and drive decisions during high-impact incidents.
Read More: The Best SRE tools in 2025
A structured approach helps you grow into an expert SRE role:
SRE is evolving rapidly with technology and business demands:
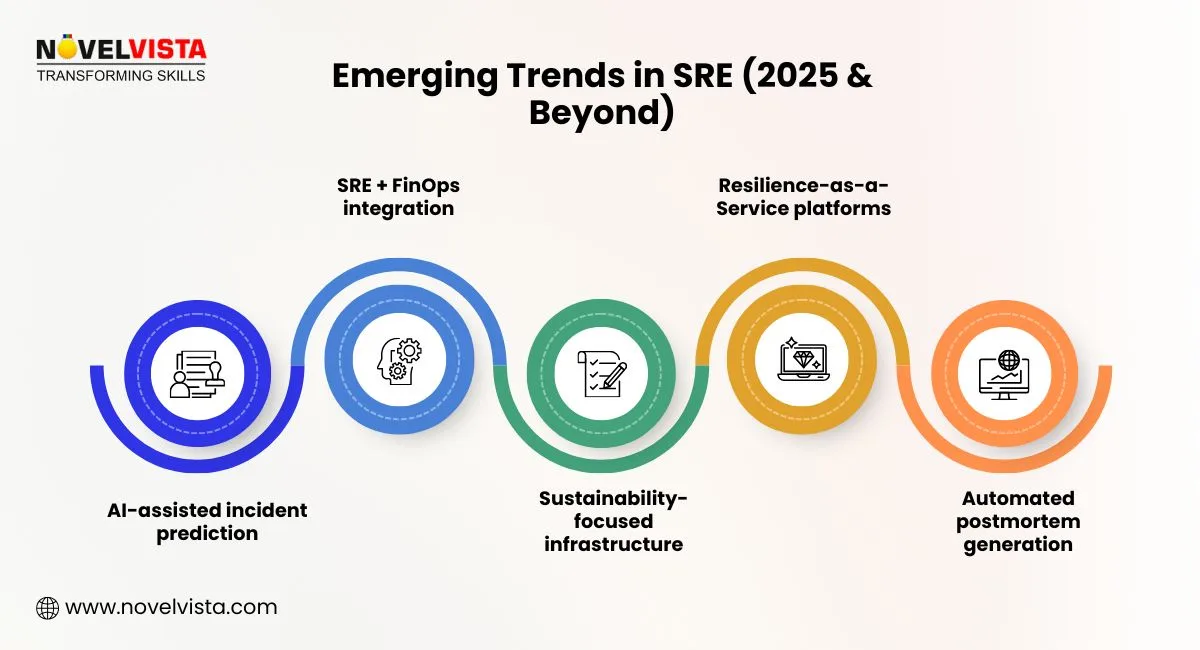
Read More: Future of SRE after 2025
Matt Zelesko, Head of Site Reliability Engineering at Google, views SRE as evolving from traditional operations to balancing velocity and reliability, especially amid rapid AI and ML advancements. He emphasizes SRE’s core mission to enable teams to move quickly while meeting reliability goals.
Zelesko highlights AI as a critical assistant for improving incident detection, mitigation, and postmortems, allowing SREs to focus on complex engineering challenges and risk management earlier in development. He also stresses expanding SRE tools and practices beyond traditional teams to empower more groups within Google to manage production infrastructure effectively.
SRE engineers are the backbone of reliable, scalable, and high-performing systems. Mastering Site Reliability Engineering Principles, core skills, and SRE roles and responsibilities enables teams to deliver excellent user experiences and measurable business impact.
Take your reliability skills further with NovelVista’s SRE Foundation and SRE Practitioner Certification Training Courses. Learn the principles, hands-on skills, and tools needed to excel as an SRE engineer. Gain practical experience in incident response, automation, monitoring, and cloud systems to drive uptime and resilience. Enroll today and lead SRE initiatives with confidence.

Author Details

Course Related To This blog
SRE Foundation and Practitioner Combo
SRE Certification Course
SRE Foundation and SRE Practitioner combo
SRE Practitioner
SRE Foundation
Confused About Certification?
Get Free Consultation Call
Stay ahead of the curve by tapping into the latest emerging trends and transforming your subscription into a powerful resource. Maximize every feature, unlock exclusive benefits, and ensure you're always one step ahead in your journey to success.


