Category | DevOps
Last Updated On 29/05/2026
The SRE Roadmap is the blueprint for mastering the future of IT reliability. In a world where system failures can lead to lost revenue, damaged reputations, and frustrated users, SRE has become the lifeline that businesses depend on. The roadmap covers essential skills like incident response, automation, scalability, and performance optimization to ensure systems run seamlessly, no matter the scale. Once exclusive to tech giants like Google, SRE is now a global standard for IT stability.
Whether you're an engineer, developer, or exploring DevOps, this roadmap will equip you with the expertise to stay ahead, build resilient systems, and be a driving force in the digital age.
Let’s break it down simply. Site Reliability Engineering (SRE) is a discipline developed by Google to ensure that services remain reliable, scalable, and efficient. It combines the logic of software development with the practical challenges of infrastructure and operations.
SRE professionals don’t just fix systems; they design systems that don’t break in the first place.
Here’s what makes the SRE roadmap special:
More importantly, the SRE roadmap helps you build a structured journey from learning the basics to mastering large-scale system design and resilience.
If you're serious about becoming a successful SRE, you must follow a clear roadmap and learning path. Let’s break it down by levels to make it simple and actionable.
This roadmap is your foundation. At this stage, focus on getting comfortable with the building blocks of system administration, programming, and cloud platforms.
Pro Tip: Don’t try to memorize everything; get your hands dirty by practicing in real environments. Try fixing broken VMs or writing small automation scripts.
Once you have your basics in place, move on to tools and practices that bring SRE to life.
Pro Tip: At this stage, try contributing to open-source SRE tools or set up a home lab using free-tier cloud services to reinforce your skills.
By the time you reach this level, you’re no longer just troubleshooting or setting up environments; you’re designing and managing large-scale systems. This stage of the SRE roadmap is all about scale, efficiency, and secure automation.
Pro Tip: Start working on real-world projects or simulations that involve auto-scaling, failover systems, and disaster recovery. That’s where true SRE skills shine.
This is where you transform from a solid SRE to a strategic leader. You’re not just executing tasks; you’re guiding others and building a culture of reliability.
Join thousands of professionals who have transformed their careers
✅ Expert-Led Learning
✅ Hands-on Practice
✅ Up to 40% Off
Before diving into the technical SRE Roadmap 2026, it's essential to become familiar with the foundational principles that underpin SRE. These are not just buzzwords, they’re your guiding lights.
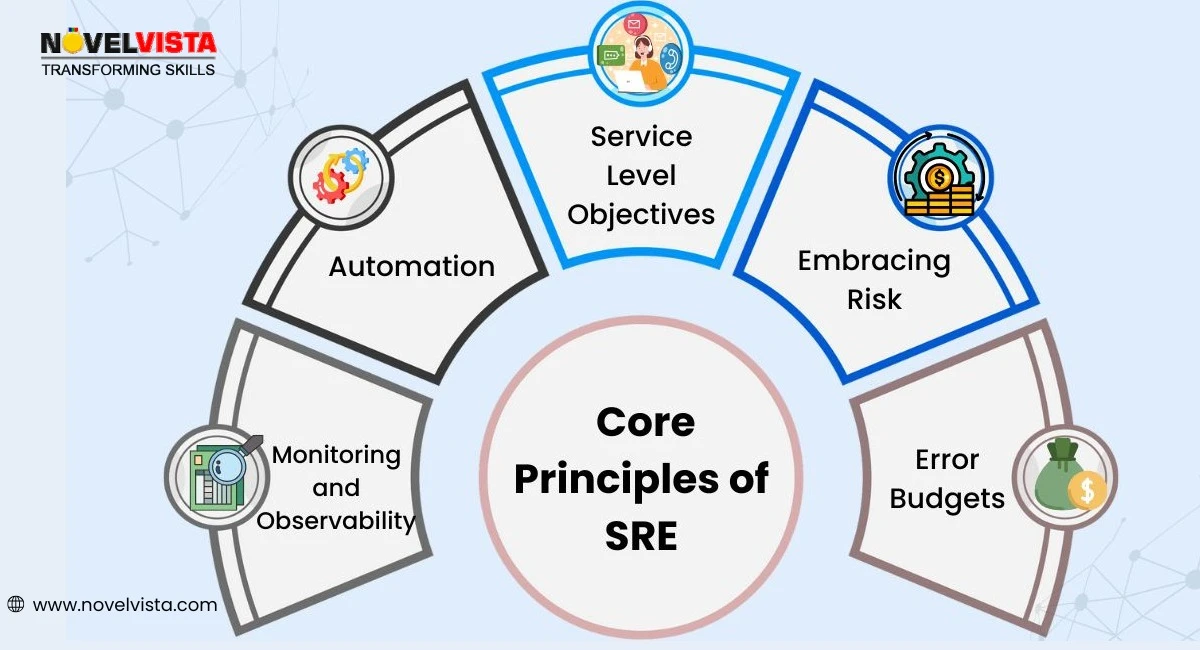
Systems will fail; it’s inevitable. SRE encourages acknowledging this fact and designing with resilience in mind. It’s about risk management, not risk elimination.
These are measurable targets for uptime, latency, or error rates. SLOs guide your efforts and help set realistic reliability goals for your systems.
This concept is genius. It allows you to balance innovation and reliability. If your system hasn’t used up its “error budget,” you’re free to push new changes. If you’ve exceeded it, it's time to stabilize.
You should avoid repetitive, manual tasks (also called toil) as much as possible. Automating deployments, monitoring, and recovery processes helps free up time for innovation.
Monitoring is about knowing when something is wrong. Observability is about knowing why. Tools like Prometheus, Grafana, and ELK help SREs gain insights into system health and behavior.
These principles will be your pillars throughout the roadmap.
This is not just training. This is transformation. At NovelVista, we don’t just teach; you evolve.
You don’t want to be left behind in 2026. The future of IT demands SRE certification that enables building fast and fixing faster. Let NovelVista get you there, faster, smarter, and more confidently.
If you're just starting, don’t get overwhelmed. The roadmap for SRE may look long, but every expert was once a beginner.
You don’t just want a job title, you want respect, impact, and recognition. And that comes only when you build the skill stack right with the roadmap.
Becoming a Site Reliability Engineer in 2026 is not just a career choice; it’s a smart investment in your future.
The digital world depends on reliability, speed, and security. Whether you’re fresh out of college or shifting from a development or sysadmin role, this roadmap gives you the path to success.
With structured learning, the right mindset, and support from experienced mentors like those at NovelVista, your transformation from learner to leader is not a distant dream; it’s your next move.

Author Details

Course Related To This blog
SRE Foundation and Practitioner Combo
SRE Certification Course
SRE Foundation and SRE Practitioner combo
SRE Practitioner
SRE Foundation
Confused About Certification?
Get Free Consultation Call
Stay ahead of the curve by tapping into the latest emerging trends and transforming your subscription into a powerful resource. Maximize every feature, unlock exclusive benefits, and ensure you're always one step ahead in your journey to success.