Category | DevOps
Last Updated On 19/02/2026

In the digital world, site reliability engineering (SRE) is no longer a luxury; it’s a necessity. As businesses push for more uptime, faster releases, and robust cloud infrastructure, the demand for SRE professionals has skyrocketed. But here's the catch: the journey into SRE can be daunting, especially for those just starting out. You might be struggling with career stagnation, facing skill gaps, or unsure about the best training path to follow.
If you're someone aiming to enter the world of reliable systems and cloud infrastructure management, SRE Certification is a must. However, without a clear training roadmap, navigating the path can feel overwhelming.
The good news? This SRE career path guide will give you a step-by-step approach to SRE certification, covering everything from foundational knowledge to advanced skills. By following this roadmap, you can confidently build the expertise required to become a successful Site Reliability Engineer, regardless of your current experience level.
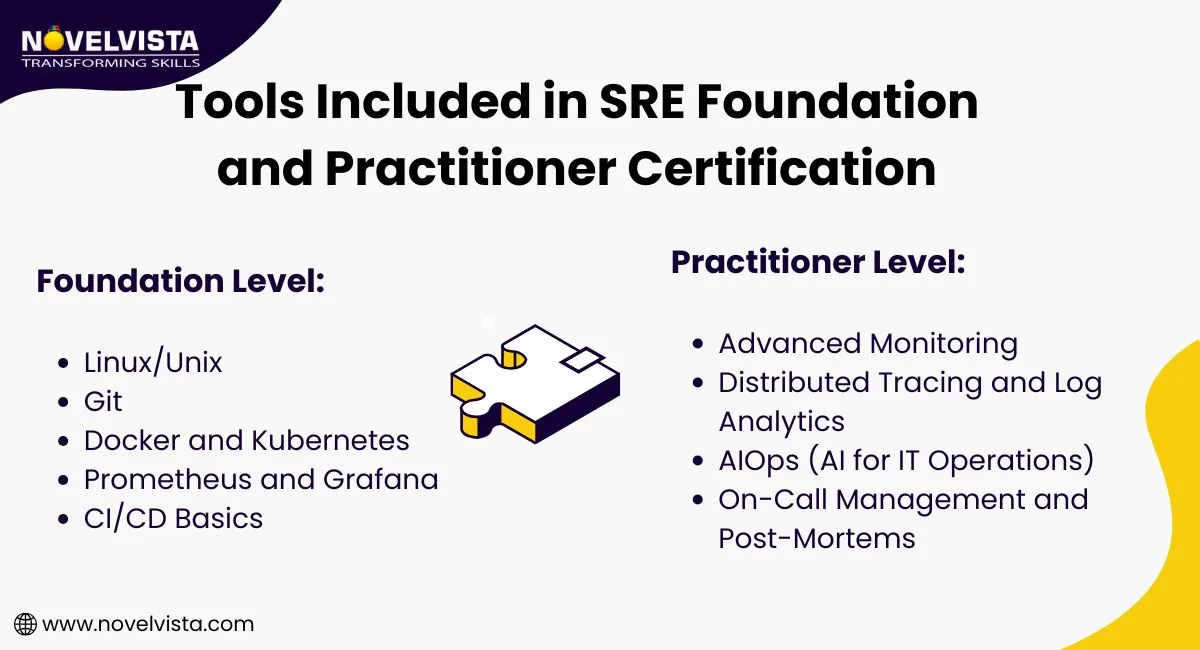
At the foundation level, you’ll get an introduction to the core concepts that power SRE and differentiate it from similar practices like DevOps. You'll build a solid understanding of the principles and culture that form the backbone of site reliability.
You'll also be introduced to the essential tools used in the industry, including:
As you move into the practitioner level, you will dive deeper into the application of SRE principles, focusing on how to implement them in real-world scenarios. This stage builds on the foundational knowledge and introduces more advanced topics that ensure you can scale services, manage incidents efficiently, and keep systems running smoothly at a larger scale.
At this level, you will refine your skills and get hands-on experience with more advanced tools and techniques:
Advance your career with the certifications and tools top SREs use to succeed.
The advanced level is where you truly become a Site Reliability Engineering leader. This phase focuses on architecting highly available systems, program management, and leading SRE teams. It’s designed for those looking to take on leadership roles within SRE and apply advanced strategies for reliability at the enterprise level.
If you're just starting with SRE, NovelVista offers a comprehensive learning path that covers foundational to advanced topics, helping you get certified and gain hands-on experience. Below are some of the best courses to get started with your SRE certification journey:
This course introduces the core concepts of Site Reliability Engineering (SRE), providing a solid foundation in principles, tools, and the culture needed for a successful SRE practice. You will explore key topics such as SLOs, SLIs, error budgets, monitoring, toil reduction, and much more.
Building on the Foundation level, this course covers advanced SRE topics like incident response, chaos engineering, observability, and service reliability at scale. You'll gain practical experience with real-world tools like Prometheus, Grafana, and Docker, and understand how to implement SRE culture within large-scale systems.
At NovelVista, we offer comprehensive SRE training across all levels, from Foundation to Advanced. Our courses are designed to provide real-world, hands-on experience using industry-standard tools like Prometheus, Grafana, Docker, and Kubernetes.
To become proficient in SRE, here’s our suggested roadmap:

Keep Advancing: Join advanced learning paths and specialist tracks such as Google Cloud SRE or Google Professional Cloud DevOps Engineer for a deeper understanding.

The SRE certification path is a structured journey that helps you grow from a beginner to a highly skilled practitioner and eventually an advanced leader in reliability engineering. By following the right learning path and gaining hands-on experience, you’ll acquire the skills necessary to excel in the ever-evolving field of site reliability.
At NovelVista, we equip you with the right tools, expertise, and mentoring to ensure that your journey to becoming a certified Site Reliability Engineer is practical, efficient, and aligned with your career goals. Don’t wait, start your journey to SRE success today!
Author Details

Confused About Certification?
Get Free Consultation Call
Stay ahead of the curve by tapping into the latest emerging trends and transforming your subscription into a powerful resource. Maximize every feature, unlock exclusive benefits, and ensure you're always one step ahead in your journey to success.


