Category | DevOps
Last Updated On 05/11/2025

Ever wondered how companies like Google, Netflix, or Amazon keep their services running smoothly 24/7 — even when millions of users are logging in, streaming, or shopping all at once? That’s where the magic of Site Reliability Engineering (SRE) in technology.
If you’ve been hearing the term but aren’t exactly sure what is SRE in technology, here’s the simple answer — it’s the practice of combining software engineering and IT operations to build reliable, scalable, and automated systems. In short, SRE makes sure that technology doesn’t just work; it keeps working no matter how big or complex things get.
SRE is gaining massive attention because modern companies can’t afford downtime. A single outage can cost millions, hurt brand trust, and frustrate customers. Through this guide, we’ll break down everything — from SRE meaning in tech, how it works, the tools involved, and why it’s becoming one of the most important roles in IT today.
Let’s clear up the confusion — what does SRE mean in technology?
In simple words, SRE or Site Reliability Engineering is a way to apply engineering principles to make IT systems more reliable and efficient.
The concept was first developed at Google, where they noticed that developers (Dev) wanted to push updates quickly, while operations (Ops) teams focused on keeping systems stable. To balance this, they created SRE — a middle ground that uses automation, monitoring, and smart processes to keep both sides happy.
Here’s what SRE meaning in tech really boils down to:
In other words, SRE in technology brings together the best of both worlds — innovation from developers and stability from operations.
Now that you know what SRE is, let’s talk about how sre in technology works. SRE runs on a set of guiding principles that make it measurable, consistent, and scalable across teams. Here are the core principles explained in simple terms:
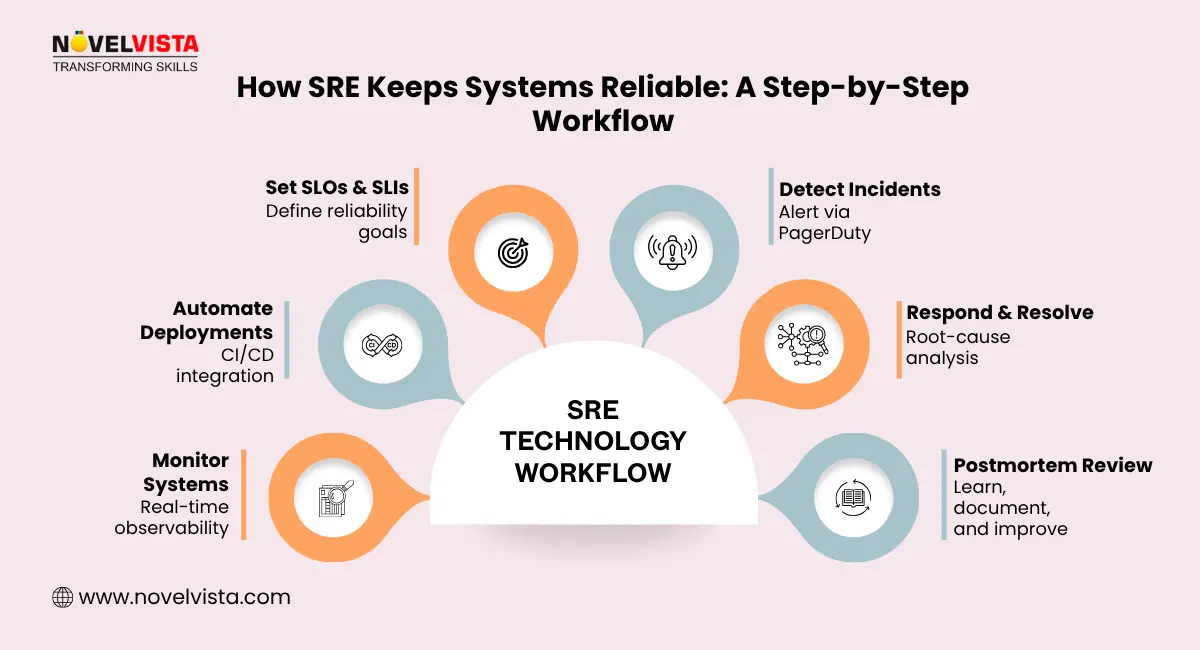
These principles turn reliability from a vague concept into something measurable and actionable — that’s the power of SRE in tech.
Must Read: Site Reliability Engineering Fundamentals
If you’re wondering what an SRE engineer actually does day to day, here’s the breakdown:
Simply put, SRE engineers are the unsung heroes of tech — they make sure that your favorite apps and websites stay fast, reliable, and available all the time.
When it comes to SRE in technology, tools are everything. They help automate tasks, monitor systems, and fix issues before users even notice something’s wrong. Mastering the right SRE technologies can make a huge difference in how effective an engineer is.
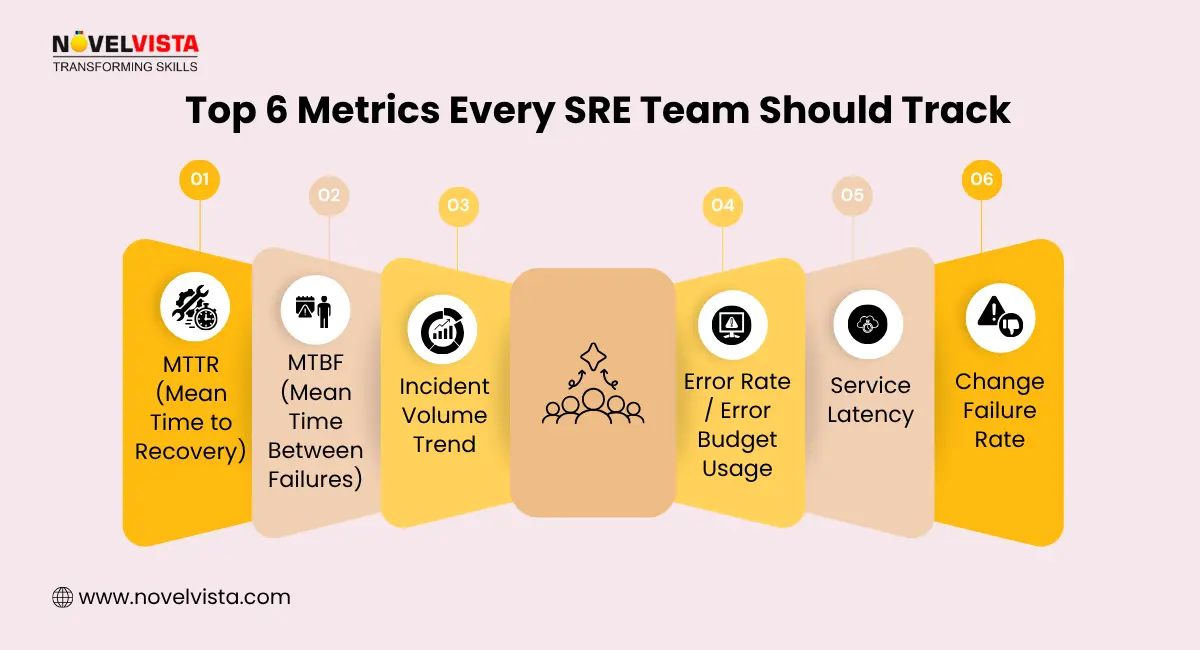
Let’s look at the most widely used SRE tech tools, grouped by purpose:
These SRE technologies form the backbone of reliability in modern organizations. Knowing how to use them makes you not just efficient, but indispensable in large-scale IT environments.
Also Read: Top Ranking SRE Tools in 2025
So, why are companies investing so much in SRE? Because the results speak for themselves. Adopting SRE in tech helps organizations turn reliability into a predictable, measurable practice rather than a guessing game.
Here’s what businesses gain when they apply SRE in technology:
In short, SRE goes beyond just keeping servers running — it’s about delivering stability, trust, and quality at every level.
Now that you understand the importance of SRE, let’s talk about the exciting part — the career opportunities.
The demand for skilled SRE professionals is skyrocketing because companies need experts who can make sure systems stay up and running. Whether you’re a developer or a sysadmin, transitioning to SRE can open doors to some of the best-paying and most impactful roles in tech.
Here’s how a typical SRE career path looks:
Check Out: Complete SRE Roadmap to Get Started in 2025
Having certifications in DevOps, Cloud, or SRE-specific programs can fast-track your growth. As technology continues to evolve, SRE is becoming one of the most future-proof career paths out there.
While SRE brings incredible value, implementing it isn’t always smooth. Many organizations struggle during the initial adoption phase.
Here are some common hurdles and how to handle them:
Once these challenges are addressed, organizations can unlock the full potential of SRE in technology — achieving both innovation and reliability without compromise.
To wrap it up — what is SRE in technology? It’s the bridge that connects development speed with operational stability. It’s how top companies ensure their systems stay reliable, scalable, and efficient.
As more organizations move to the cloud and adopt complex distributed systems, SRE in tech will only become more essential. It’s not just a role; it’s a mindset that every modern IT team needs.
If you’re aiming to grow your career in IT operations or system reliability, learning SRE principles and tools is the best place to start.
Because in today’s digital world, reliability isn’t optional — it’s everything.
Next Step: The Future of SRE
Ready to kickstart your SRE journey? Enroll in NovelVista’s SRE Foundation Certification Training — your pathway to mastering reliability engineering principles, automation practices, and real-world resilience strategies. Our expert-led sessions, hands-on labs, and industry case studies ensure you gain practical, job-ready skills.
Join NovelVista today and elevate your career as a certified Site Reliability Engineer — where reliability meets innovation!

Author Details

Confused About Certification?
Get Free Consultation Call
Stay ahead of the curve by tapping into the latest emerging trends and transforming your subscription into a powerful resource. Maximize every feature, unlock exclusive benefits, and ensure you're always one step ahead in your journey to success.


