Category | DevOps
Last Updated On 27/11/2025

In 2024, global downtime costs crossed $400 billion, with the average outage costing enterprises $9,000 per minute. What’s even more surprising? Nearly 70% of service failures were caused not by technology, but by poor processes, unclear responsibilities, and outdated operational practices.
So the real question is:
If systems are becoming smarter, why are failures becoming more frequent?
This is exactly where the SRE Framework steps in.
Before we dive deeper, ask yourself:
In this blog, we will learn how the SRE Framework actually works—and why it’s becoming the backbone of modern digital operations.
The SRE Framework is a structured approach that blends software engineering principles with operations to build highly reliable, scalable, and automated systems.
Originally developed by Google, Site Reliability Engineering (SRE) introduced a new way of thinking:
treat operations as an engineering problem.
An effective SRE assessment framework typically includes:
Unlike traditional IT operations, the SRE Framework is not just a process—it’s a culture shift that prioritizes reliability, monitoring, and intelligent automation.
Modern systems are incredibly dynamic, operating across containerized environments, multi-region deployments, and cloud-native architectures where even a few seconds of delay can impact thousands of users. With expectations of near-perfect uptime, organizations today face immense pressure to keep services consistently reliable. Systems now scale faster than teams can manage, while manual operations simply cannot keep pace with the speed and complexity of modern development. Add to that the challenges of microservices—each introducing new dependencies and potential points of failure—and the rising demand for reliability in AI-driven services, and it becomes clear why a structured approach is essential. Without an SRE-driven reliability framework in place, teams spend their days firefighting issues instead of innovating, ultimately slowing down growth and compromising customer trust.
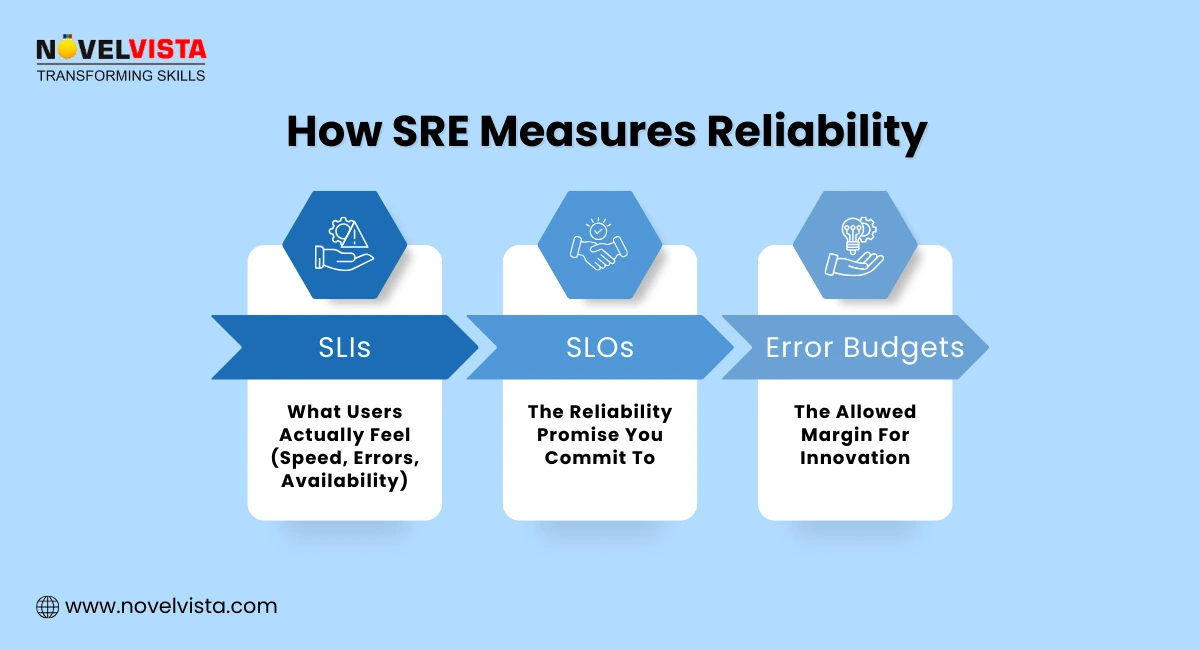
At the heart of the SRE Framework are SLIs and SLOs—simple yet powerful tools for defining reliability. SLIs measure key aspects of system behavior like latency, error rate, throughput, and availability, while SLOs set the acceptable performance targets for these indicators. Together, they replace guesswork with clarity, helping teams quantify what “good performance” truly means and align on reliability expectations.
An error budget defines how much failure a system can safely tolerate, creating a practical balance between innovation and reliability. This uniquely SRE concept ensures that teams can continue to ship new features without compromising stability, keeping business and engineering priorities aligned. When the error budget is fully consumed, deployments slow down to restore system health, making the SRE Framework both disciplined and engineering-friendly.
A strong SRE practice includes:
The goal is not to assign blame—it’s to learn and enhance reliability using a consistent SRE assessment framework.
Monitoring shows you what happened, while observability helps you understand why it happened. Together, they form the backbone of actionable reliability insights. Key capabilities include golden signals like latency, saturation, errors, and traffic, along with distributed tracing, automated alerting, and intelligent dashboards that make issues easier to detect and resolve. Layered on top is automation—a core SRE principle that reduces toil, speeds up recovery, and minimizes human-caused errors to keep systems running smoothly.
The SRE Framework ensures systems can handle growth through:
Teams see issues early—before customers do.
Facto |
SRE Framework |
Traditional IT Ops |
Approach |
Focuses on applying engineering principles to operations for predictable and scalable reliability. |
Relies primarily on established processes and procedures to manage day-to-day operations. |
Culture |
Encourages a blameless, collaborative environment where teams learn from failures and improve continuously. |
Often operates in silos with limited collaboration and a blame-oriented approach to incidents. |
Monitoring |
Emphasizes observability and proactive insights to understand system behavior and prevent issues. |
Mostly reactive monitoring, detecting problems only after they impact users. |
Deployment |
Uses automated CI/CD pipelines to ensure faster, safer, and repeatable releases. |
Depends on manual approvals and traditional deployment processes, which can be slower and error-prone. |
Reliability |
Sets measurable reliability targets using SLOs to ensure consistent service performance. |
Relies on general expectations without clearly defined or measurable targets. |
Focus |
Aims to reduce manual toil and increase overall system reliability through automation and process improvements. |
Primarily focuses on maintaining operations without necessarily improving efficiency or scalability. |
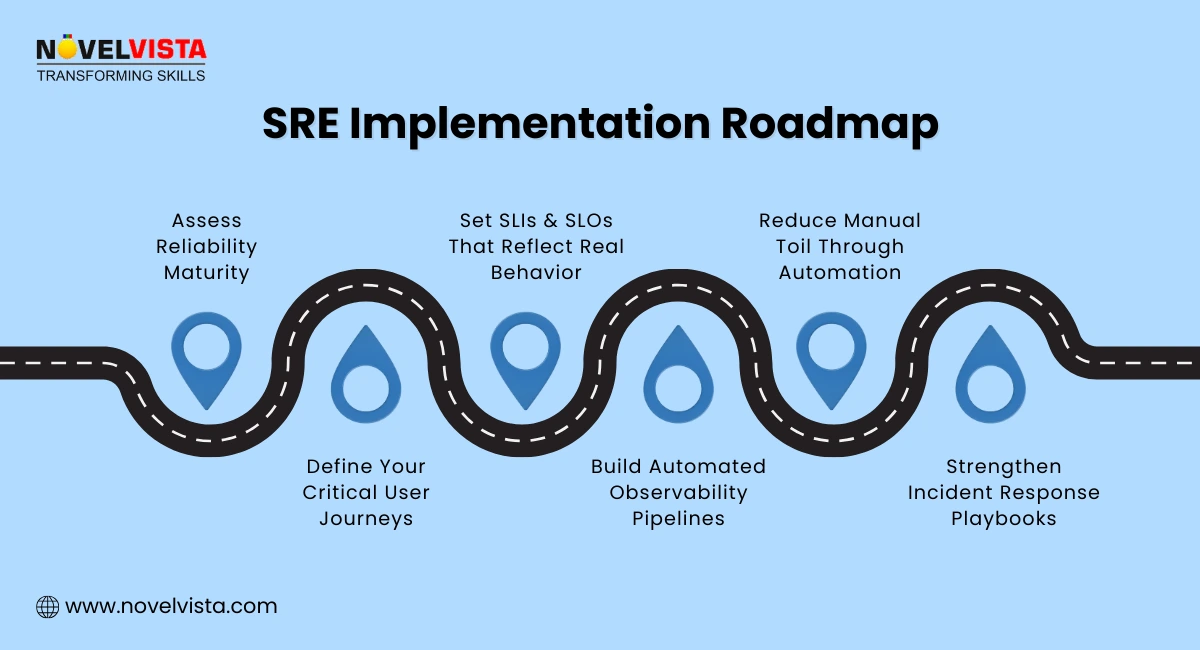
Begin with an SRE assessment framework to understand where your organization currently stands. Evaluate key areas like monitoring maturity, automation levels, SLO readiness, incident response processes, and overall team culture and skills. This initial assessment becomes your reliability baseline, helping you identify gaps and prioritize improvements with clarity and direction.
Choose the metrics that matter most to your service.
Example:
This forms the reliability contract between engineering and the business.
Set clear error budgets to define how much failure your system can safely tolerate. This step is crucial because it prevents teams from over-engineering, protects innovation pipelines from unnecessary slowdowns, and creates shared accountability between engineering and operations. It ensures that reliability decisions are balanced, data-driven, and aligned with business goals.
Your monitoring and observability stack should include logs, metrics, traces, distributed monitoring, scalable alerting, and clear dashboards to keep systems transparent and predictable. Prioritizing proactive alerts over reactive firefighting ensures issues are caught early—before they escalate into user-impacting failures.
Toil is manual, repetitive, and low-value work.
Use automation for:
Automation is where the SRE Framework becomes powerful.
Establish clear incident response protocols by defining on-call rotations, escalation policies, runbooks, and communication flows. Having this structure in place ensures teams know exactly what to do during an incident, reducing confusion and significantly improving Mean Time to Recovery (MTTR).
Run active reviews, analyze failure patterns, and update processes using insights from your SRE assessment framework.
Reliability improves not from tools alone—but from disciplined iteration.
1. Over-engineering Too Early
2. Ignoring Cultural Alignment
3. Poor Metric Selection
4. Skipping Error Budgets
Avoiding these mistakes ensures the SRE Framework is actually effective, not theoretical.
Your Shortcut to High-Availability, Low-Stress Operations
Organizations that adopt SRE principles experience:
This is why the SRE Framework has become a gold standard across cloud-native, DevOps, and enterprise IT environments, and because of its impact on organization.
Modern systems demand modern reliability strategies. The SRE Framework delivers this by offering a structured, measurable, and automation-driven approach to reliability engineering. When combined with an effective SRE assessment framework, organizations gain the clarity, discipline, and confidence needed to operate complex systems without fear of unexpected failures.
If your goal is to deliver consistent, stable, and high-performance digital experiences, then now is the time to embrace the SRE Framework—not later.
Ready to strengthen your reliability engineering skills?
Join NovelVista’s SRE Foundation Training or SRE Practitioner Training Certification and build a solid understanding of SLOs, error budgets, automation, incident response, and real-world SRE practices used by top-performing tech teams. Designed for DevOps engineers, IT operations professionals, and cloud specialists, this course helps you confidently implement the SRE Framework and drive reliability across modern digital systems.
Start your SRE journey today!

Author Details

Confused About Certification?
Get Free Consultation Call
Stay ahead of the curve by tapping into the latest emerging trends and transforming your subscription into a powerful resource. Maximize every feature, unlock exclusive benefits, and ensure you're always one step ahead in your journey to success.


