Category | DevOps
Last Updated On 07/05/2025
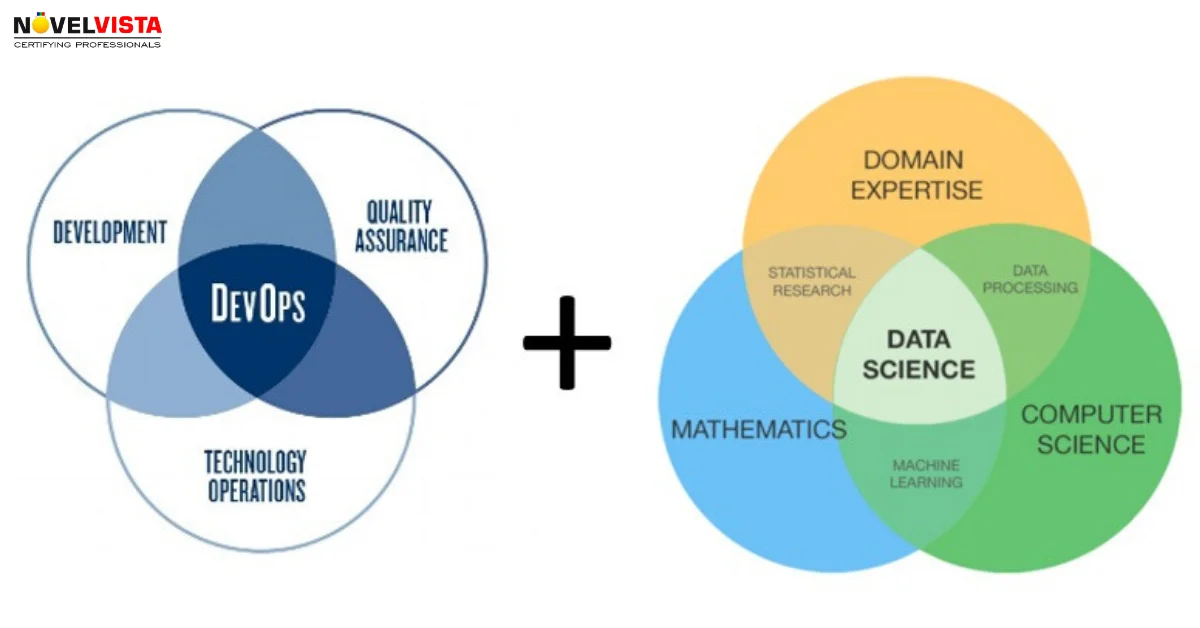
DevOps and Data Science are two of the hottest fields in tech, but they provide very different purposes. DevOps concentrates on collaboration, automation and integration to enhance the software delivery and Information Technology operations. Data Science uses statistical and analytical methods to extract insights from the data.
In the unlikely event that you were going to lay up a production-level machine learning pipeline, the data science work would have a position at the beginning when it came to planning and model preparation.
An ordinary pipeline will eventually shift from information science to foundation errands, usually at the perfect moment to take models to creation. This is, intuitively, where the data science team transfers responsibility to another team member, such as DevOps.
Although this isn’t normally the condition, to an ever-increasing extent, researchers are also being approached to deal with conveying models to generations. Based on the algorithmia, the lion’s share of data scientists report investing over 25% of their energy in model sending alone. Specifically, you can check this with the help of taking the gender at what number of information researchers' work postings incorporate things, including Kubernetes, Docker, and EC2 under important knowledge.
One of the straightforward answers to this query is that model serving is the foundation issue, not the data science issue. You can see this with the help of simply looking at the stacks used for each:
There are obviously a few data scientists who like DevOps and can work cross-practically, yet they are uncommon. The truth here is that it gets easy to state the cover between data science andDevOpsis now and again overestimated.
To flip the facts, is it okay to expect the DevOps designer to have the option to plan another model engineering or to have a huge amount of involvement in hyper parameter running? There are likely DevOps Engineers who have those data science aptitudes, and everything is learnable. Still, it's odd to consider those obligations the space of your DevOps Groups.
Data scientists more than likely do not get the field to stress over auto-scaling or composing Kubernetes shows, so for what reason do businesses cause them to do it?
Different businesses have fundamental misunderstandings and need to understand how complex model serving is. The attitude is often just wrapping a model in Flask in good enough for now.
The reality is serving the models at any scale, which includes resolving some infrastructure challenges. You can take the following example:
So, in the current scenario, it's essential to become reasonable. Machine Learning framework is gaining new ideas and practices. Two years ago, Uber had just revealed Michelangelo, their cutting-edge internal machine learning foundation. The ML framework's playbook is currently being produced from a variety of perspectives. Nevertheless, there are still many examples where an association can separate the concerns of DevOps and information science without requiring the kind of design resources found in an Uber.
Cortex was designed to delineate data science from DevOps and to automate all of the infrastructure code they were writing. Since open sourcing, they have worked with the data science teams who have adopted and implemented it, and their experiences have informed our approach.
It is crucial to understand the distinct roles and responsibilities of Data Science and DevOps in order to separate them effectively. Data Science primarily focuses on extracting insights from data through statistical analysis and machine learning algorithms, while DevOps is centred on software development, deployment, and operations.
Here are some key steps to separate Data Science and DevOps:
They conceptualize the handoffs among the data science, DevOps and product engineering with the easy, abstract architecture they refer to as the Model-API-Client:
Data scientists train and export a model during the model phase. In order to generate and filter model predictions, they also write the predict () method.
After that, they turn this model over to the API phase, when the DevOps function takes full accountability for it. The model is just a Python function to the DevOps function; it has to be transformed into a microservice, containerized, and deployed.
After the model-microservice becomes online, developers can query it just like they would any other API. The model is merely another online service in their eyes.
While there are other ways to divide the responsibilities of data science and engineering, the Model-API-Client design shows that it is possible to do so without creating costly end-to-end platforms or adding extra overhead. Creating distinct handoff points between ML pipeline tasks allows data scientists to focus on what they do best, which is data science.
Explore how DevOps and Data Science are reshaping industries.
In conclusion, the intersection between Data Science and DevOps or the Devops culture for data science poses both challenges and opportunities for organizations navigating the complexities of machine learning pipeline deployment.
While there is a growing trend towards blurring the lines between these domains, it's essential to recognize and respect the unique skill sets and responsibilities of each. Businesses often need to pay more attention to the complexities of model serving, assuming that wrapping a model in Flask is sufficient.
However, deploying and scaling models at the production level requires addressing infrastructure challenges such as automated updates, auto-scaling, monitoring, and cost management.
Author Details

Confused About Certification?
Get Free Consultation Call
Stay ahead of the curve by tapping into the latest emerging trends and transforming your subscription into a powerful resource. Maximize every feature, unlock exclusive benefits, and ensure you're always one step ahead in your journey to success.


