Category | DevOps
Last Updated On 29/05/2026

In a world where a few seconds of downtime can cost millions and damage brand reputation instantly, reliability is no longer optional — it is a business mandate. This is why Site Reliability Engineering (SRE) has become critical in 2026. If you’re exploring the SRE full form or trying to understand the real SRE meaning, it starts with one idea: building systems that stay reliable at scale.
Site reliability engineering's meaning goes beyond keeping systems “up.” It focuses on automation, measurable reliability targets, and fast recovery when failures happen. Understanding what the SRE process is helps teams balance rapid releases with stable production systems.
SRE originated at Google in the early 2000s when traditional operations couldn’t keep up with massive system growth. By treating operations as a software problem, Google created the foundation for modern SRE practices used across cloud-native environments today.
This guide explains the SRE meaning, its key principles, and the responsibilities of an SRE professional. We’ll also dive into how SRE plays a crucial role in modern enterprises and how it differs from traditional DevOps practices.
At its core, the SRE meaning revolves around engineering reliability into production systems through defined metrics, disciplined incident response, and ongoing optimization.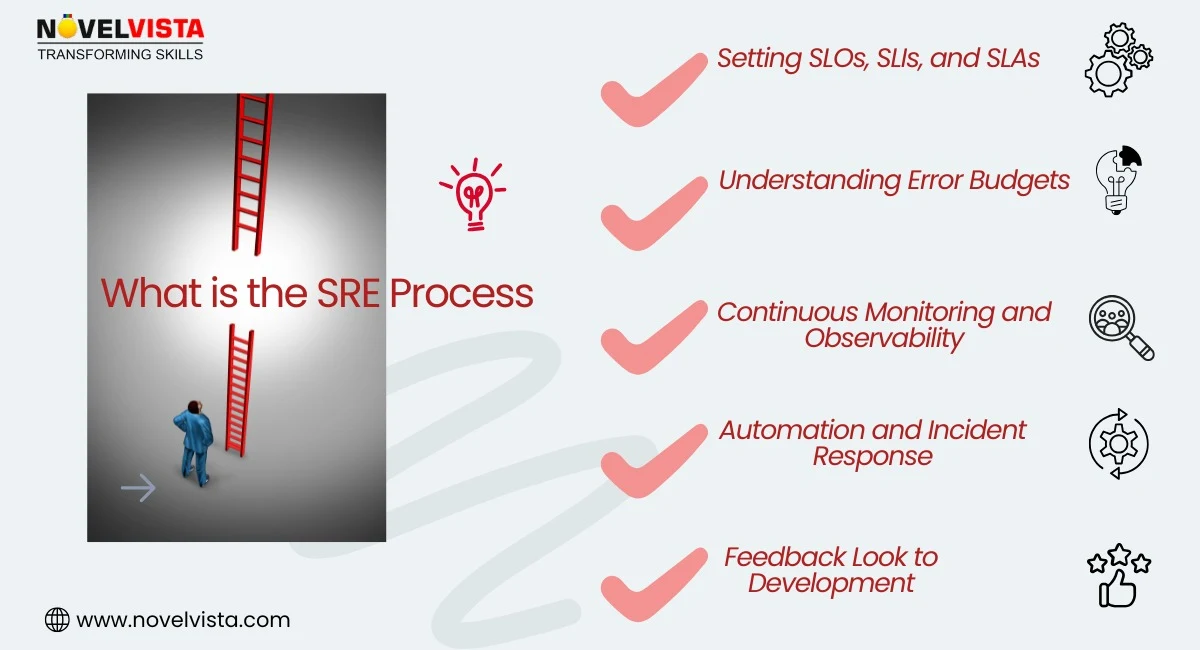
SREs define Service Level Indicators (SLIs) to measure actual system performance, such as latency, error rates, and availability. Service Level Objectives (SLOs) set clear reliability targets. These measurable benchmarks ensure that reliability is quantified and tracked consistently.
Error budgets represent the acceptable level of system unreliability within a given timeframe. They help balance fast feature releases with operational stability. If the error budget is exhausted, reliability improvements take priority over new development.
A core principle of the SRE process is reducing operational toil. SREs automate repetitive tasks such as deployments, scaling, monitoring configurations, and remediation workflows. Automation minimizes human error and increases efficiency.
Across multiple team engagements, structured toil audits typically reveal that 35–45% of operational effort can be automated within 3–6 months using scripting and infrastructure as code.
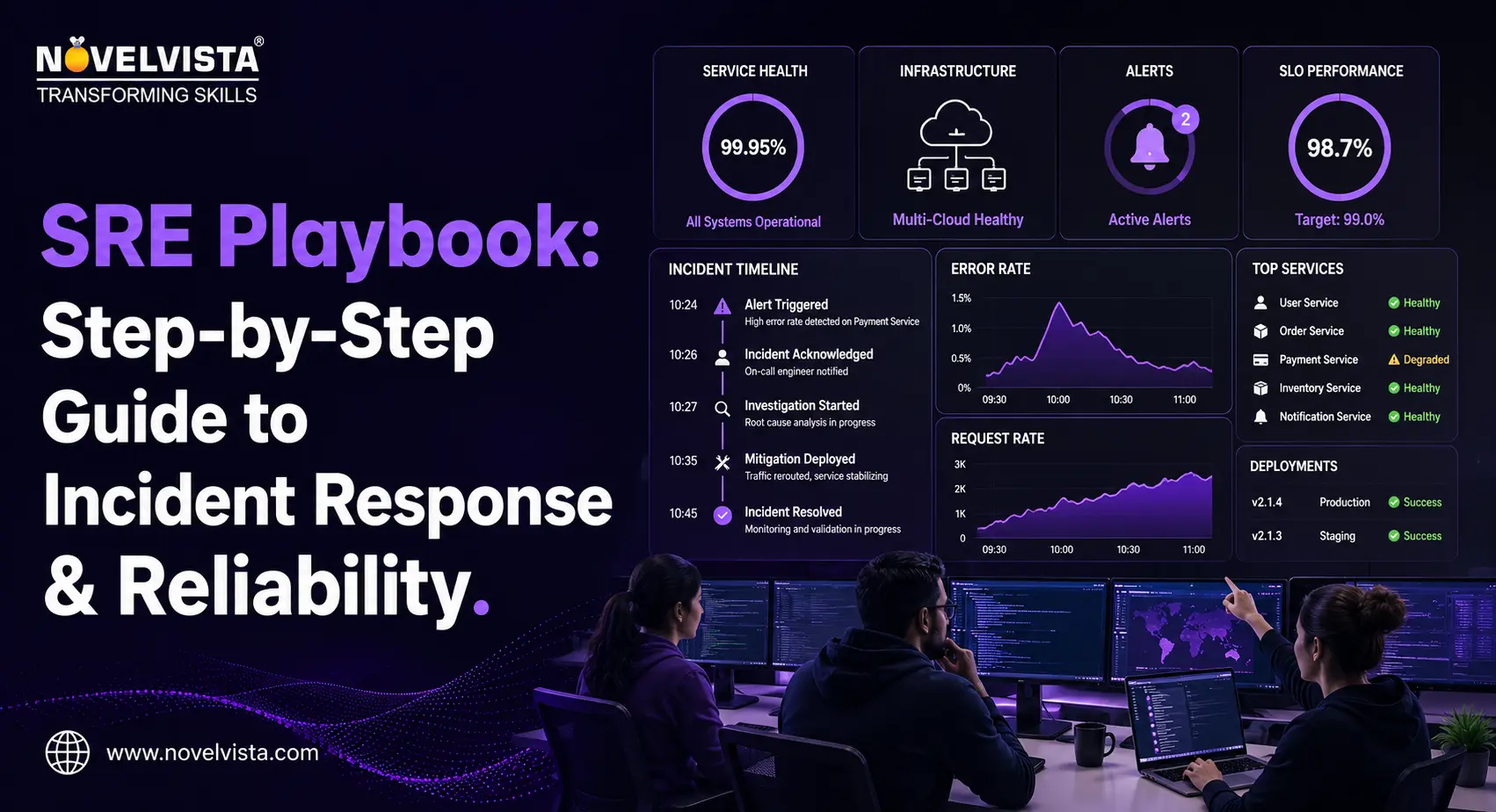
SRE teams establish structured procedures for detecting, diagnosing, and resolving incidents. This includes well-documented playbooks and runbooks that guide teams during outages, ensuring faster recovery and minimal service disruption.
When failures occur, the focus is not on assigning blame but on identifying root causes and strengthening the system. Blameless post-mortems promote a culture of transparency, accountability, and continuous improvement.
Continuous monitoring ensures systems meet performance and availability targets. Observability tools provide deep insights into system behavior, helping teams detect anomalies early and prevent cascading failures.
SRE teams anticipate future growth by forecasting infrastructure needs. Capacity planning ensures that systems can handle traffic spikes, product launches, and long-term scaling without performance degradation.
Site reliability engineering's meaning becomes clearer when you look at how it operates inside real organizations. SRE works by setting reliability targets, measuring performance continuously, balancing innovation with stability, and using automation to eliminate operational friction.
Instead of reacting to outages, SRE teams proactively design systems that anticipate failure, scale with demand, and recover quickly. Reliability is treated as a measurable engineering objective, not an abstract goal.
In our SRE implementation workshops, teams typically discover that over 35% of production incidents stem from unclear SLO definitions or alert misconfigurations. When structured SLIs and error budgets are introduced, we often see incident noise reduce by 25–40% within the first quarter of adoption.
An SRE has a wide range of responsibilities, with a strong focus on system reliability, performance, and automation. Here are some of the key responsibilities of SRE that come with the role:
Ensuring that systems are actively monitored for reliability, performance, and availability. SREs configure alerts to detect issues early and trigger incident response procedures.
When an issue arises, SREs are responsible for resolving it as quickly as possible while minimizing downtime. They work cross-functionally with engineering teams to implement solutions and prevent future incidents.
Managing and automating the deployment process ensures that new software updates are deployed reliably without disrupting the system.
SREs must assess the capacity of systems to handle current and future loads, ensuring the system can scale effectively as traffic increases.
Automating manual tasks is at the heart of SRE. This includes developing tools to streamline system management, reduce operational toil, and improve system reliability.
After an incident, SREs conduct post-mortem reviews to identify root causes, evaluate how the incident was handled, and implement improvements for the future.
But reliability does not come from tools alone. It comes from skilled professionals who understand what is the SRE process and can apply it effectively. A great SRE combines engineering depth with operational awareness. They think in systems, automate relentlessly, and treat reliability as a measurable outcome—not a guess.
A strong SRE in 2026 demonstrates:
Deep Technical Foundations: Strong knowledge of distributed systems, cloud platforms, networking, and performance engineering.
Data-Driven Decision Making: Ability to define SLOs, track SLIs, manage error budgets, and use observability tools effectively.
Automation Mindset: Commitment to reducing manual toil through scripting, infrastructure as code, and CI/CD integration.
Incident Leadership: Calm, structured handling of incidents with clear communication and a post-incident learning culture.
Collaboration with Development Teams: Bridging DevOps speed with production stability by embedding reliability into the software lifecycle.
Through delivering SRE certification programs and mentoring reliability teams, we consistently see that organizations adopting formal SRE models improve release confidence within two to three quarters.
Improved System Reliability: By defining clear SLOs and managing error budgets, SRE ensures systems remain reliable even during high traffic, releases, or unexpected failures.
Faster Incident Recovery: Standardized incident response, automation, and post-incident reviews help teams restore services quickly and reduce repeat issues.
Reduced Operational Toil: SRE focuses on automating repetitive manual tasks, freeing engineers to work on meaningful improvements instead of firefighting.
Better Balance Between Speed and Stability: Understanding what is the SRE process allows teams to ship features faster without sacrificing production stability.
Scalability for Cloud-Native Systems: SRE practices are designed for modern distributed and cloud environments, making it easier to handle growth and traffic spikes.
Stronger Collaboration Between Teams: SRE bridges development and operations, aligning engineering efforts around shared reliability goals.
Ultimately, the SRE meaning is about turning reliability into a measurable, manageable, and scalable advantage for modern businesses.
While SRE and DevOps share some common goals, such as improving system reliability and efficiency, there are key differences in their approach.
While SRE and DevOps have distinct approaches, they are not mutually exclusive. SREs and DevOps engineers often collaborate to build and maintain systems that are both fast and reliable. DevOps practices help accelerate development, while SRE principles ensure these changes are reliable and stable.
At NovelVista, we understand how crucial SRE is for modern organizations. Whether you’re a beginner looking to break into the field or an experienced professional aiming to refine your skills, we offer training programs that cater to all levels.
At NovelVista, we’re committed to providing comprehensive training that empowers you to become an expert in SRE, cloud-native systems, and reliability engineering. Whether you're preparing for certification or simply enhancing your knowledge, we’ve got you covered.
Evaluate your SRE readiness with a quick self-check!
✅ SRE Skills Check
✅ Skill Ratings & Guidance
✅ Beginner-Friendly Tool
To wrap up, Site Reliability Engineering (SRE) is not just a technical practice; it’s a mindset that ensures systems are built to be reliable, scalable, and efficient. With the growing complexity of cloud-native systems and the demand for high availability, SRE has become one of the most important roles in modern IT.
In 2025, the demand for SRE professionals will continue to rise as companies seek to balance innovation with system stability. If you're looking to dive into SRE, start building your foundational knowledge, experiment with SRE practices on small projects, and get certified with NovelVista to open doors to career growth and opportunities.

Author Details

Confused About Certification?
Get Free Consultation Call
Stay ahead of the curve by tapping into the latest emerging trends and transforming your subscription into a powerful resource. Maximize every feature, unlock exclusive benefits, and ensure you're always one step ahead in your journey to success.