Category | CLOUD and AWS
Last Updated On 16/05/2025
The scalability of an app is the capacity of the system to handle the load of the application and ensure the smooth functioning of the app with the increasing user load. Whether your app has one user or million users, it should be capable enough to handle large data, high request rates, velocity, etc., to offer a seamless app experience.
Having a scalable application is equally important as its features and user interface. It becomes even more important if your app is going to serve more than 10 million users in the future.
Suppose you’ve built aweb applicationand started getting few customers. After some feedback and suggestions, you are ready with a full-fledged product. Now, your marketing team shares your app on product hunt to acquire new customers. Suddenly, thousands of visitors are using your app and at one point they are unable to use your app.
You’ve tested your app and it is working fine. So what happened?
“This is not a bug but a problem of scalability. Your cloud architecture is not designed to scale with increasing load.”
There are many ways to scale e-commerce websites or web-application, but usually, people aren’t sure which scaling plan they should opt for and how to implement it effectively.
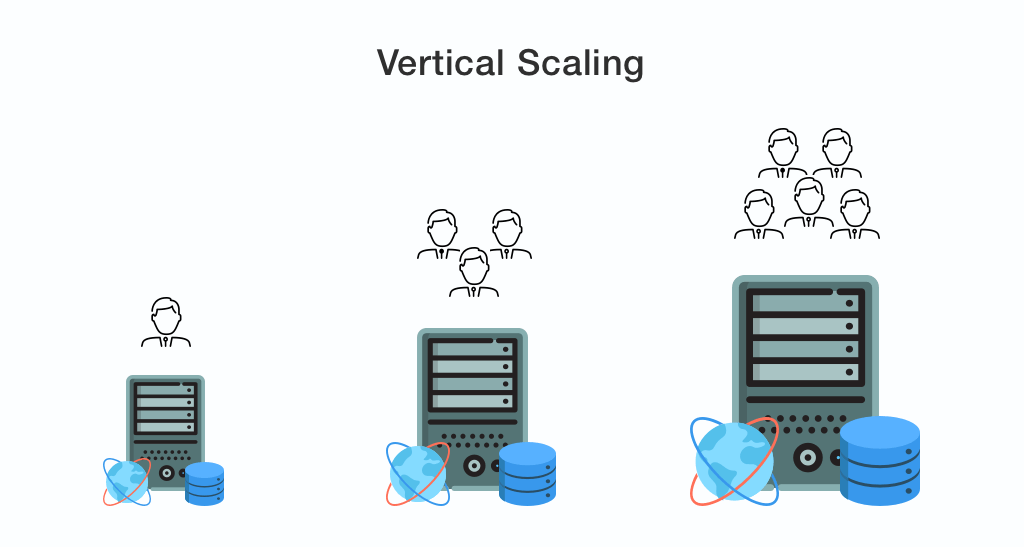
Scaling up or Vertical scalingmeaning adding more power to your existing machine or system. In case, if you are using a traditional data center for managing the current workload, then it is best to leverage the cloud for your on-premises solutions to scale your app efficiency under a limited budget.
In generalvertical scalingincludesadding processing power, memory to the physical machine running the server, optimizing the algorithms, and application code.Vertical scaling can be an ideal option for small and middle-size applications.
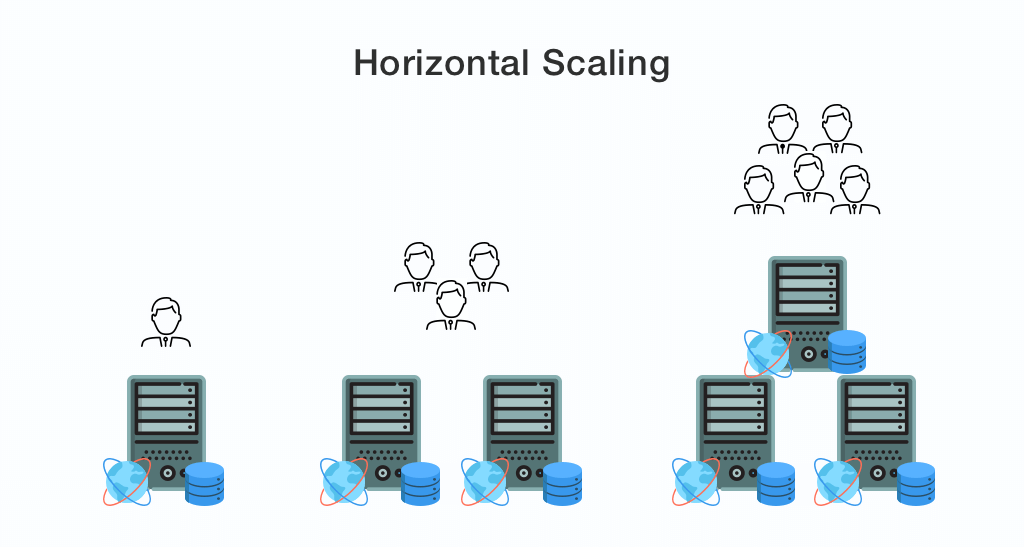
Scaling out or horizontal scalingmeans expanding your systems by getting additional resources into your process. In simple words, if you are already managing the workload on the cloud and still need to expand its efficiency then you need to use additional services to manage the load. This is where you need to expand your cloud architecture by adding more units of small capacity to spill the workload on multiple machines.
You are the only one operating the app on the localhost. The initial progress can be very simple asinstalling an applicationin a box. Here, you need to utilize the following AWS services to get started.

Amazon Machine Image (AMI) gives the information required to launch an instance, which is a virtual server in the cloud. You can specify an AMI during the launch of an instance. An AMI includes a template for the root volume for the instance, launch permissions that control which AWS accounts can use the AMI to launch instances, and a block device mapping that specifies the volumes to attach to the instance when it’s launched.

Amazon Elastic Compute Cloud provides the scalable computing capacity in the AWS cloud. This eliminates the hardware upfront so that you can develop and deploy applications faster.
Amazon Virtual Private Cloud gives a provision to launch AWS resources in a virtual network. It gives complete control over the virtual networking environment including a selection of IP address range, subnet creation, the configuration of route tables and network gateways.
Amazon Route 53 is a highly available and scalable cloud DNS web service. Amazon Route 53 effectively connects user requests to infrastructure running in AWS – such as Amazon EC2 instances, Elastic Load Balancing load balancers, or Amazon S3 buckets.
Here you need a bigger box. You can simply choose the larger instance type which is called vertical scaling. At the initial stage, vertical scaling is enough but we can’t scale vertically indefinitely. Eventually, you’ll hit the wall. Also, it doesn’t address failover and redundancy.
First, you need to choose the database as users are increasing and generating data. It’s advisable to start with SQL Database first because of the following reasons:
Note, you can choose the NoSQL database if your users are going to generate a large volume of data in various forms.
At this stage, you have everything in a single bucket. This architecture is harder to scale and complex to manage in the long run. It’s time to introduce the multi-tier architecture to separate the database from the application.
When users increase to 100, Database deployment is the first thing that needs to be done. There are two general directions to deploy a database on AWS. The foremost option is to use a managed database service such as Amazon Relational Database Service (Amazon RDS) or Amazon Dynamo DB and the second step is to host your database software on Amazon EC2.
Amazon Relational Database Service (Amazon RDS) makes it easy to set up, operate, and scale a relational database in the cloud. Amazon RDS provides six familiar database engines to choose from, including Amazon Aurora, Oracle, Microsoft SQL Server, PostgreSQL, MySQL, and MariaDB.
As per current architecture, you may face availability issues. If the host for your web app fails then it may go down. So you need another web instance in another Availability Zone where you will put the slave database to RDS.

ELB distributes the incoming application traffic across EC2 instances. It is horizontally scaled, imposes no bandwidth limit, supports SSL termination, and performs health checks so that only healthy instances receive traffic.
This configuration has 2 instances behind the ELB. We can have 1000s of instances behind the ELB. This is Horizontal Scaling.
At this stage, you’ve multiple EC2 instances to serve thousands of users which ultimately increases your cloud cost. To reduce the cost, you have to optimize instances’ usage based on varying loads.
To upgrade performance and efficiency, you’ll need to add more read replicas to RDS. This will take the load off the write master database. Furthermore, you can reduce the load from web servers by moving static content to Amazon S3 and Amazon CloudFront.

Amazon S3 is object-based storage. It is not attached to the EC2 instance which makes it best suitable to store static content, like javascript, CSS, images, videos. It is designed for 99.999999999% of durability and can store multiple petabytes of data.

Amazon CloudFront is a Content Delivery Network(CDN). It retrieves data from the Amazon S3 bucket and distributes it to multiple data center locations. It caches content at the edge locations to provide our users with the lowest latency access.
Furthermore, to reduce the load from database servers, you can use DynamoDB(managed NoSQL database) to store the session state. For caching data from the database, you can use Amazon ElastiCache.

Amazon DynamoDB is a fast and flexible NoSQL database service for applications that need consistent, single-digit millisecond latency. It is a completely managed cloud database and supports document and key-value store models.
Amazon ElastiCache is a Caching-as-a-Service. It removes the complexity associated with deploying and managing a distributed cache environment. It’s a self-healing infrastructure if nodes fail new nodes are started automatically.
At this stage, your architecture is quite complex to be managed by a small team, and without proper monitoring, analyzing it’s difficult to move forward.
Now that the web tier is much more lightweight, it’s time for Auto Scaling!
“Auto Scaling is nothing but an automatic resizing of computing clusters based on demand.”
Auto Scaling enables “just-in-time provisioning,” allowing users to scale infrastructure dynamically as load demands. It can launch or terminate EC2 instances automatically based on Spikes in Traffic. You pay only for the resources which are enough to handle the load.
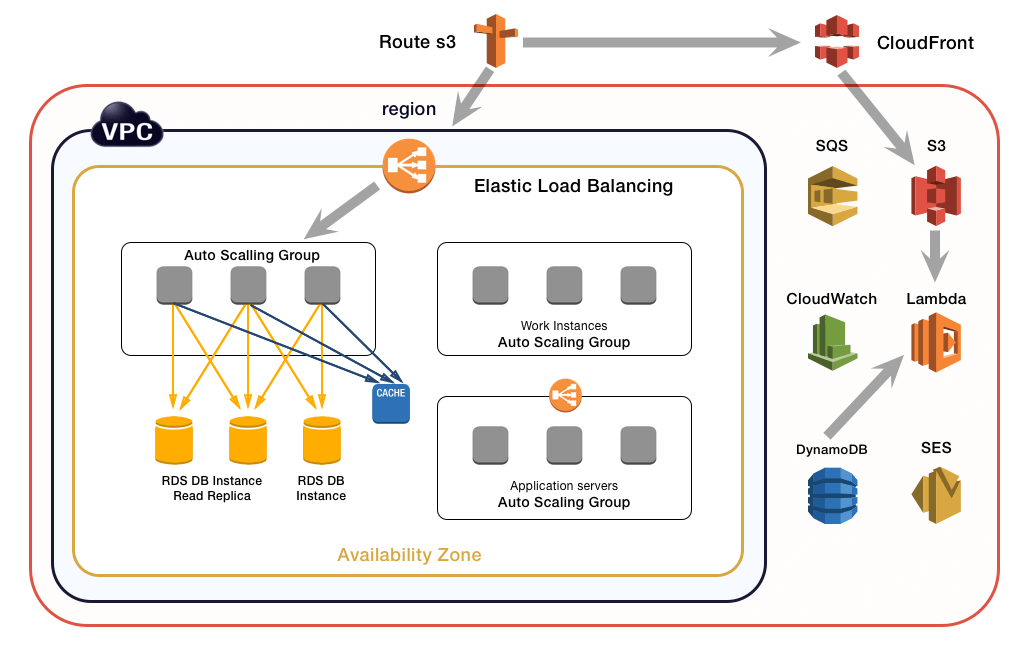
AWS CloudWatch provides a rich set of tools to monitor the health and resource utilization of various AWS services. The metrics collected by CloudWatch can be used to set up alarms, send notifications, and trigger actions upon alarms firing. Amazon EC2 sends metrics to CloudWatch that describe your Auto Scaling instances.
The autoscaling group can include multiple AZs, up to as many as are in the same region. Instances can pop up in multiple AZs not just for scalability, but for availability.
We need to add monitoring, metrics, and logging to optimize Auto Scaling efficiently.
Squeeze as much performance as you can from your configuration. Auto Scaling can help with that. You don’t want systems that are at 20% CPU utilization.
The infrastructure is getting big, it can scale to 1000s of instances. We have read replicas, we have horizontal scaling, but we need some automation to help manage it all, we don’t want to manage each instance. Here some automation tools:
AWS OpsWorks provides a unique approach to application management. Additionally, AWS OpsWorks auto-heals application stack, giving scaling based on time or workload demand and generates metrics to facilitate monitoring.
AWS Elastic Beanstalk is a service that allows users to deploy code written in Java, .NET, PHP, Node.js, Python, Ruby, Go, and Docker on familiar servers such as Apache, NGINX, Passenger, and IIS.

AWS Cloud Formation provides resources using a template in JSON format. You have the option to choose from a collection of sample templates to get started on common tasks.

AWS Code Deploy is a platform service for automating code deployment to Amazon EC2 instances and instances running on-premises.
To serve more than 1 million users you need to use Service Oriented Architecture(SOA) while designing large-scale web applications.
In SOA, we need to separate each component from the respective tiers and create separate services. The individual services can then be scaled independently. Web and application tiers will have different resource requirements and different services. This gives you a lot of flexibility for scaling and high availability.
AWS provides a host of generic services to help you build SOA infrastructure quickly. They are:

SQS acts as glue for a distributed and highly scalable system. When a system is stitched together via asynchronous messaging, different parts of the system can scale or fail independently. Imagine a job that needs to be processed in three steps. If you have independent fleets that are responsible for each step and step two fails, that job could remain in the queue until step two is fixed rather than be canceled completely.

SNS is a pub-sub service for sending messages to different AWS services. Subscribers of a topic receive messages published to that topic. For example, you can have CloudWatch fire messages to an SNS topic, and any AWS Lambda function that is subscribed to that topic will be triggered. While both SNS and SQS are messaging services on the AWS platform, SNS can push messages to multiple subscribers, eliminating the need to periodically check or “poll” for updates.

AWS Lambda runs your code written in Java, Node.js, and Python without requiring you to provision or manage servers. Lambda will run and scale your code with high availability, and you pay only for the compute time you consume in increments of 100 milliseconds. The code you upload will become Lambda functions, which can be triggered by various events on the AWS platform. Lambda functions can be thought of as first-class compute resources that you can insert into your AWS architecture. A common use case is to have a Lambda function listening to S3 events and performing custom processing logic when objects are uploaded into S3. AWS Lambda is a fairly new but powerful service on the AWS platform.
Between five to ten million users, you might run into issues with your database due to contention on the write master. There are several methods of mitigation, but they essentially require you to further decouple in the database layer.
These methods include:
Database federation is about separating databases by function. For example, you might choose to store data for your forum, users, and products in three distinct databases. Again, this allows your components to scale independently. This database strategy can complement the SOA strategy. For example, you might decide you want to keep data belonging to separate services in separate databases. On the flip side, this architecture is more complex and requires you to write more sophisticated queries to fetch data.
If your data is still too large to be managed under a federation schema, you can considersharding. This is horizontal scaling at the database tier. With sharding, you store data across multiple databases and spread the records evenly. You can have users with last names in the A through M range in one database and the rest in another. Sharding allows you to scale larger than a federation, but it requires more logic in your application to dynamically change the target database depending on the data you need.
Lastly, if you have independent tables in a relational database, you could consider moving that data to a NoSql database such as Amazon DynamoDB. A relational database has overhead associated with maintaining relationships between data. So why take on that overhead when you don’t need to extract relationships from your data? DynamoDB is a managed, scalable, and high-performance key-value store. Like RDS, DynamoDB takes care of administrative tasks for you so you can focus on high-value tasks. Data is stored across multiple facilities across a region to achieve high availability. DynamoDB also scales automatically with the size of data.
The decision about how to approach scaling should be made upfront because you never know when you are going to get popular! Also, crashing (or even just slow) pages leave your users unhappy and your app with a bad reputation. It ultimately affects your revenue.
I hope this blog series has given you some food for thought regarding scaling on the AWS platform. For additional resources, please refer our course on AWS to learn how to build anadvanced AWS architecture
Learn the Best Practices, Tools, and Architecture to Scale Your Application Seamlessly on AWS.
Author Details

Confused About Certification?
Get Free Consultation Call
Stay ahead of the curve by tapping into the latest emerging trends and transforming your subscription into a powerful resource. Maximize every feature, unlock exclusive benefits, and ensure you're always one step ahead in your journey to success.


