Category | DevOps
Last Updated On 12/06/2026

Configuration drift is one of the biggest headaches for infrastructure teams. One server works perfectly, another behaves differently, and suddenly deployments start failing for no clear reason. This is where Puppet architecture becomes extremely valuable.
Modern DevOps teams rely on automation to keep systems consistent across thousands of servers. Tools like Puppet help teams manage infrastructure using code instead of manual configuration. If you have ever wondered what is Puppet, what is Puppet software, or what is Puppet used for, the answer lies in its ability to automate and standardize infrastructure.
In our DevOps automation training sessions, many engineers report configuration drift as a recurring production issue. Teams managing 200–500 servers often adopt Puppet to standardize environments and reduce manual configuration errors.
This article explains Puppet architecture, how it works, the components involved, and how Puppet architecture in DevOps helps teams maintain stable, scalable infrastructure. Before diving into the details, here is a quick overview of the key concepts.
Topic |
Key Insight |
|---|---|
What is Puppet |
An open-source configuration management tool for infrastructure automation |
Puppet architecture |
Master–agent model that manages infrastructure centrally |
Key components |
Puppet Server, Puppet Agent, Facter, Manifests, Modules |
How Puppet works |
Agents collect system data and pull configuration updates from the server |
DevOps value |
Ensures consistent infrastructure and prevents configuration drift |
With this context in mind, it becomes easier to understand what is Puppet in DevOps and why organizations use it for infrastructure automation.
To understand how does Puppet work, we first need to look at the overall structure of Puppet architecture.
Puppet uses a pull-based master–agent architecture. This means the central Puppet server defines configurations, while agents installed on servers periodically check for updates and apply them automatically.
Key elements of Puppet architecture
The architecture mainly includes two major components:
In Puppet architecture, agents communicate with the server to receive instructions about how their systems should be configured.
How the pull-based model works
Unlike push-based tools that send instructions directly, Puppet works differently. Agents periodically contact the server and ask:
Is my system configuration still correct?
If changes are required, the Puppet server sends updated instructions. Some important characteristics of Puppet architecture in DevOps include
Because of this design, Puppet enables centralized infrastructure control while still maintaining flexibility across large environments.
This approach makes Puppet architecture particularly effective in enterprise infrastructure environments where consistency and security are important.
To fully understand how does Puppet work, it is important to understand the components that make up Puppet architecture.
Each component plays a specific role in managing infrastructure configuration.
Puppet Architecture Components
Component |
Role |
|---|---|
Puppet Server / Master |
Stores manifests and modules and compiles configuration catalogs |
Puppet Agent |
Runs on nodes and retrieves configuration update |
Facter |
Collects system information such as OS and network details |
Manifests |
Configuration files written in Puppet DSL |
Modules |
Reusable collections of Puppet configuration code |
Catalog |
Compiled instructions sent to nodes |
SSL / Certificate Authority |
Secures communication between the server and agent |
Let’s break down these components further.
The Puppet server is the central controller in Puppet architecture. It performs several important tasks:
All infrastructure rules are stored here.
The Puppet Agent runs on every managed node. Its responsibilities include:
This component ensures infrastructure always matches the desired configuration.
Facter is a system information tool used by Puppet. It collects details such as:
These system facts help Puppet determine the correct configuration for each node.
Manifests are configuration files written using the Puppet DSL language. They define:
These .pp files describe the desired state of infrastructure.
Modules are collections of Puppet manifests and files. They allow teams to reuse configuration code across environments.
For example, a module may contain configuration for:
Modules improve efficiency in Puppet architecture in DevOps by enabling reusable automation.
The catalog is the compiled configuration instructions generated by the Puppet server It contains a list of actions that must be applied to a specific node. When the Puppet agent receives the catalog, it applies these instructions.
Security is an important part of Puppet architecture. Communication between agents and the server is protected using SSL certificates.
This ensures:
These components together form the foundation of what is Puppet software and how it manages large infrastructure environments.
In infrastructure automation training labs, learners typically build Puppet modules to manage web servers and databases. Reusable modules often reduce configuration scripting effort by nearly 40% in production environments.
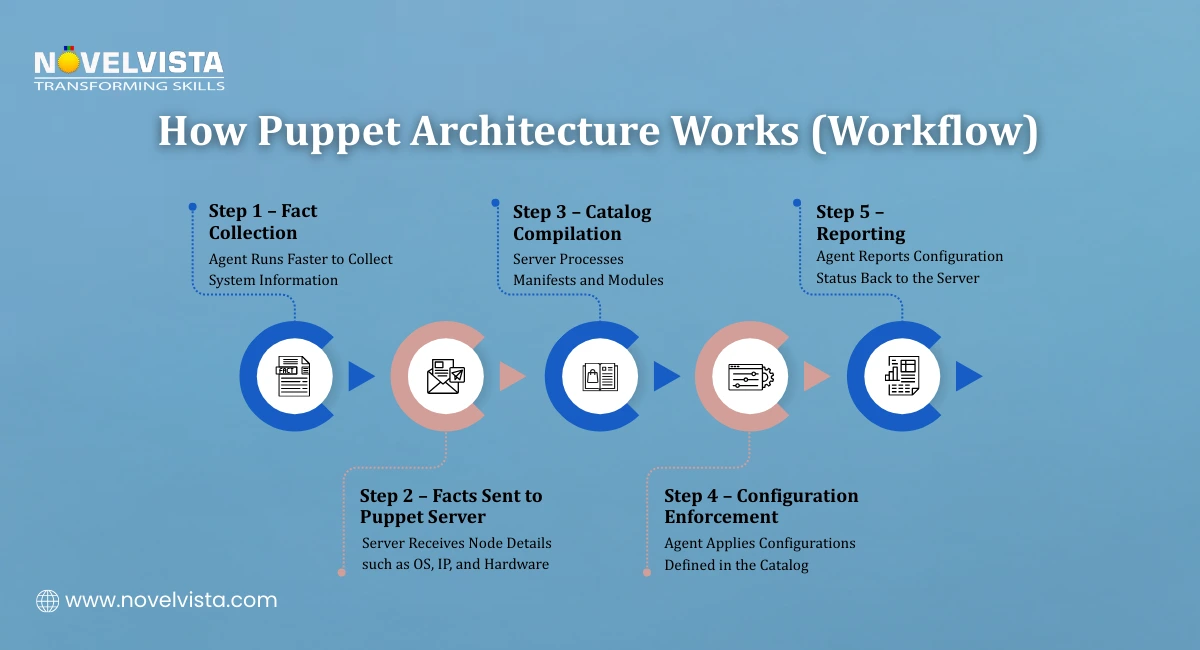
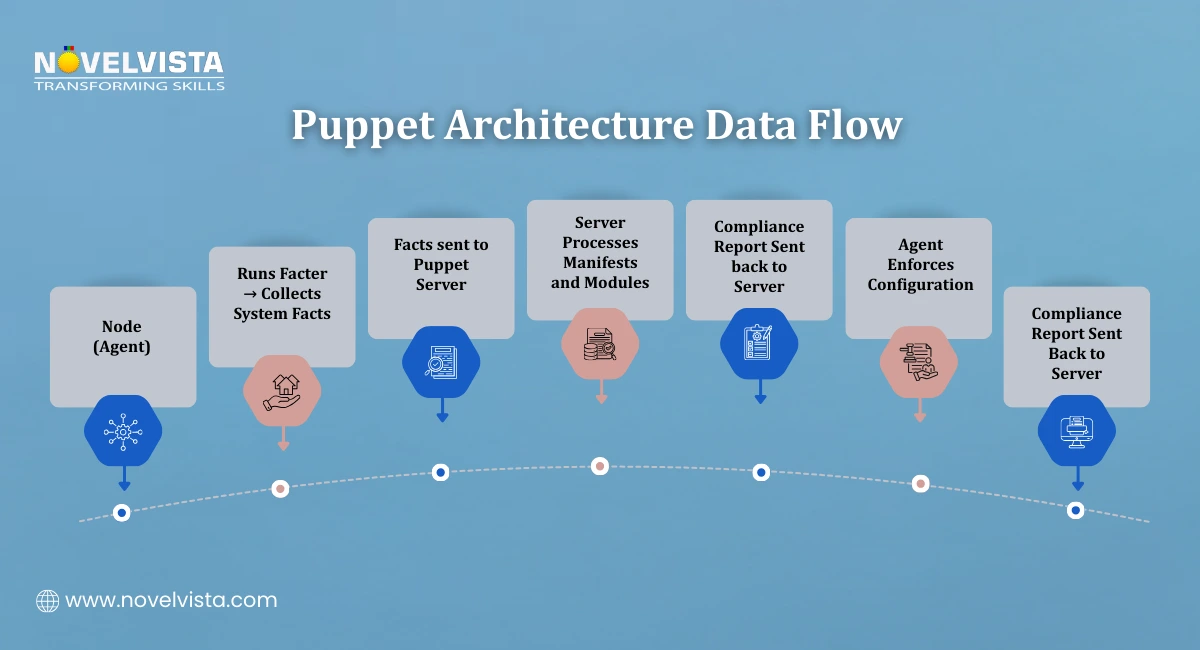
Understanding the workflow helps explain how does Puppet work in real-world DevOps environments. The Puppet configuration process follows a structured cycle.
Step 1: Fact Collection
The process begins when the Puppet Agent runs Facter. Facter gathers system information such as:
Operating system details
Network configuration
Hardware specifications
IP address
These details are called facts. The agent sends these facts to the Puppet Server.
Step 2: Catalog Compilation
The Puppet server processes the received facts and compiles a configuration catalog. This catalog is created using:
Puppet manifests
Modules
Infrastructure policies
The compiled catalog defines the desired configuration state for that specific node.
Step 3: Configuration Enforcement
The Puppet Agent receives the catalog and applies the required changes. Puppet uses an idempotent approach.
This means:
If the system already matches the desired configuration, nothing changes.
If differences exist, Puppet automatically fixes them.
This behavior ensures systems remain consistent.
Step 4: Reporting
After applying configurations, the Puppet Agent sends a report back to the Puppet server. These reports help administrators track:
Configuration changes
Compliance status
Infrastructure health
This automated feedback loop makes Puppet architecture highly reliable for infrastructure management.
Once teams understand Puppet architecture, the next question usually becomes: what makes Puppet useful in real DevOps environments? The answer lies in its automation capabilities and strong infrastructure management features.
Puppet was designed to support Infrastructure as Code (IaC), which means infrastructure configurations are written and managed using code instead of manual setup. Several Puppet features make this possible.
Infrastructure as Code (IaC)
One of the most important Puppet features is the ability to define infrastructure using code. With Puppet, administrators write configuration rules in manifests. These files describe the desired state of the system.
For example, a manifest can define:
Which packages must be installed
Which services should run
Which configuration files must exist
This approach ensures every system follows the same configuration. Because of this capability, Puppet architecture in DevOps allows teams to treat infrastructure the same way they treat application code.
Version-Controlled Configuration
Puppet configurations are typically stored in version control systems such as Git.
This allows teams to:
Track infrastructure changes
Review configuration updates
Roll back problematic changes
Version control also improves collaboration between DevOps teams working on infrastructure automation.
Stateless and Scalable APIs
Another advantage of Puppet is its stateless architecture. This means the Puppet server can scale horizontally to support very large environments. Enterprise deployments often use Puppet architecture to manage thousands of servers simultaneously.
Large organizations have reported Puppet deployments managing more than 100,000 nodes, demonstrating how scalable the platform can be.
DevOps Tool Integration
Puppet also integrates easily with modern DevOps pipelines.
Common integrations include:
Jenkins for CI/CD automation
Docker for containerized environments
Kubernetes orchestration platforms
These integrations help teams combine configuration management with modern deployment pipelines.
Multi-Cloud and Hybrid Infrastructure Support
Modern infrastructure environments often combine multiple cloud providers with on-premise systems.
Puppet supports these environments by providing:
Cloud automation
Hybrid infrastructure management
Cross-platform configuration enforcement
These Puppet features make Puppet highly suitable for enterprise DevOps automation.
Across multiple DevOps certification programs, Puppet is frequently discussed alongside tools like Ansible and Chef. Many enterprise teams still prefer Puppet for policy-driven infrastructure management in large server environments.
Learn how to create Puppet modules, understand directory structures,
and automate real infrastructure configurations using practical Puppet DSL examples.
Organizations managing complex infrastructure often rely on Puppet architecture because it provides several operational advantages.
The benefits become especially clear when managing hundreds or thousands of servers.
Automated Configuration Management
Manual configuration of servers is time-consuming and error-prone. With Puppet architecture, administrators define configurations once and apply them automatically across all systems.
This eliminates repetitive manual work.
Prevention of Configuration Drift
Configuration drift happens when systems gradually diverge from the intended configuration. Puppet prevents this problem by constantly checking system configurations. If a node deviates from the desired state, Puppet automatically corrects it.
This self-correcting behavior makes Puppet architecture in DevOps extremely reliable.
Centralized Infrastructure Control
Puppet provides a centralized way to manage infrastructure. Administrators can define policies in one location and apply them across the entire environment. This centralized model simplifies the management of large infrastructures.
Faster Infrastructure Provisioning
Automation significantly speeds up infrastructure deployment.
Organizations using Puppet automation have reported:
Up to 85% faster server provisioning
Around 60% reduction in deployment time in large-scale environments
These improvements allow DevOps teams to deliver infrastructure quickly and reliably.
Self-Healing Infrastructure
Another major advantage of Puppet is its ability to maintain system health automatically. If a configuration changes unexpectedly, Puppet detects the issue and restores the correct configuration.
This ability helps maintain stable environments. Because of these benefits, many enterprises use Puppet architecture as a core part of their infrastructure automation strategy.
Today, DevOps teams have several configuration management tools available. Despite this competition, Puppet continues to play an important role in infrastructure automation.
There are several reasons why Puppet architecture remains widely used.
Mature Automation Ecosystem
Puppet has been used in infrastructure automation for many years. During this time, it has developed a large ecosystem of:
This mature ecosystem makes Puppet reliable for large organizations.
Enterprise-Scale Infrastructure Support
Many modern DevOps tools focus on smaller cloud-native environments. However, Puppet was designed to handle large infrastructures.
This is why Puppet architecture in DevOps is often used in enterprises managing thousands of servers.
Strong Integration with DevOps Pipelines
Puppet integrates well with modern development workflows.
For example, teams can combine Puppet with:
This allows organizations to automate both application deployment and infrastructure configuration.
Hybrid and Multi-Cloud Environments
Large organizations rarely operate in a single environment.
Many infrastructures include:
Puppet’s architecture works well in these hybrid environments. These capabilities explain why Puppet remains relevant even as new DevOps tools emerge.
Managing infrastructure manually becomes difficult as systems grow larger. Configuration inconsistencies, deployment delays, and environment differences can quickly create operational problems.
This is why Puppet architecture continues to play an important role in modern DevOps practices. By combining Puppet Server, Puppet Agents, manifests, modules, and automated workflows, organizations can manage thousands of systems consistently.
Professionals attending infrastructure automation training often highlight Puppet’s audit-friendly configuration tracking. Version-controlled manifests allow teams to review historical changes and support compliance checks during internal audits.
Understanding Puppet architecture in DevOps helps teams build scalable and reliable infrastructure automation strategies.

Next Step: Start Your DevOps Automation Journey
If you want to understand how tools like Puppet fit into modern automation pipelines, NovelVista’s DevOps Foundation Certification Training is a great place to begin. The program covers core DevOps concepts, CI/CD workflows, infrastructure automation, and collaboration practices used by modern engineering teams. Through practical learning and real-world examples, professionals gain the skills needed to work confidently in DevOps environments and implement automation effectively.
Author Details

Course Related To This blog
Certified DevOps Developer
Certified DevOps Architect
Confused About Certification?
Get Free Consultation Call
Stay ahead of the curve by tapping into the latest emerging trends and transforming your subscription into a powerful resource. Maximize every feature, unlock exclusive benefits, and ensure you're always one step ahead in your journey to success.