Category | DevOps
Last Updated On 30/09/2025

In today’s fast-paced tech world, the SRE model is helping organizations balance rapid innovation with rock-solid reliability. By combining software engineering and IT operations, the SRE model, along with key principles like Service Level Objectives (SLOs), error budgets, and automation, ensures teams deliver both speed and stability. But how do you move from theory to practice? Let’s dive deeper into the core elements of the SRE model, including essential performance measures, real-world tools, and how it compares to DevOps in achieving operational excellence.
The core objective of Site Reliability Engineering (SRE) is to use automation to build self-healing systems. Highly automated systems help bridge the gap between the development team who makes the products and the operations team who hosts and maintains the platforms.
A vital principle of the SRE approach is that site reliability engineers write code themselves. This is a significant shift from the traditional operations approach, but it is crucial for making SRE work. Google relies on metrics to ensure site reliability. Engineers spend enough time writing code to update and maintain their automated systems.
For example, a site reliability engineer should spend half of their time on regular operations tasks like working on tickets.SREs who write code to create and maintain the platforms their software runs on tend to follow more DevOps best practices. They run code through CI/CD pipelines, practice infrastructure as code, and use monitoring and alerting to ensure system health.
Fundamentally, the SRE paradigm combines traditional operational duties with software engineering methodologies. It places a strong emphasis on using automation, monitoring, and proactive management to create scalable and dependable systems. Among the fundamental ideas of the SRE model are:
SRE Goals
The core SRE goals focus on building systems that are reliable, scalable, and efficient while reducing manual work through automation. These SRE goals also emphasize proactive monitoring, effective incident management, and maintaining a balance between innovation and stability to ensure seamless user experiences.
In this approach, a centralized SRE team manages all operational responsibilities across the organization.
Focus: Provides end-to-end coverage, enables the team to detect recurring patterns across multiple projects, and supports comprehensive, organization-wide reliability strategies.
SREs or small SRE pairs are assigned directly to development teams.
Focus: Works alongside developers to integrate reliability best practices throughout the software development lifecycle, ensuring performance and stability are built into the product from the start.
SRE teams take ownership of specific critical services within the organization.
Focus: Include designing system architecture, setting up monitoring, handling incidents, planning capacity, and managing changes for the services under their purview.
SREs concentrate on the reliability and quality of a particular user-facing product rather than only the underlying services.
Focus: Enhances user experience by addressing issues that directly affect customers, even if they fall outside the typical service boundaries.
Combines elements of multiple SRE models to suit organizational needs.
Focus: Some SREs are embedded in development teams, while others manage centralized or service-specific responsibilities, allowing flexibility to balance broad oversight with focused expertise.
Adopting Site Reliability Engineering (SRE) and exploring different SRE models can deliver measurable value across your organization:
Deciding if Site Reliability Engineering (SRE) suits your organization depends on your systems, culture, and technical capabilities:
Evaluate your platforms and team skills: large internal systems and technically skilled teams benefit most. Training may be needed to bridge gaps, whether upskilling developers on infrastructure or enabling admins to embrace coding practices.
SRE roles are in demand now. Don’t get left behind. Check your readiness before others seize the opportunity.
1. Enhanced Client Experience
User happiness and retention are directly impacted by reliability. Businesses may provide more dependable services, minimize downtime, and improve the overall customer experience by adopting the SRE model. Increased trust and loyalty result from this, which eventually leads to more revenue sources.
Organizations may improve incident response times and streamline operations with SRE's emphasis on proactive monitoring and automation. Businesses may reduce risks, decrease downtime, and maximize resource usage by investing in strong monitoring tools, anomaly detection systems, and incident response procedures.
In contrast to conventional methods that place more emphasis on stability than speed, SRE promotes a constant development and experimentation mentality. Organizations may encourage innovation by setting up explicit SLOs and error budgets. This will help development teams deploy new features more rapidly and adapt to market needs on time.
The SRE model's built-in incident response, proactive monitoring, and disaster recovery procedures assist to reduce risks and guarantee that legal requirements are followed. Organizations may protect their financial stability and reputation by promptly detecting and resolving any possible weaknesses.
The SRE model helps to connect IT operations with more general business objectives by establishing precise SLOs and error budgets. When IT provides the infrastructure and support required to spur innovation, widen the market, and provide better customer experiences, it turns into a growth engine for businesses.
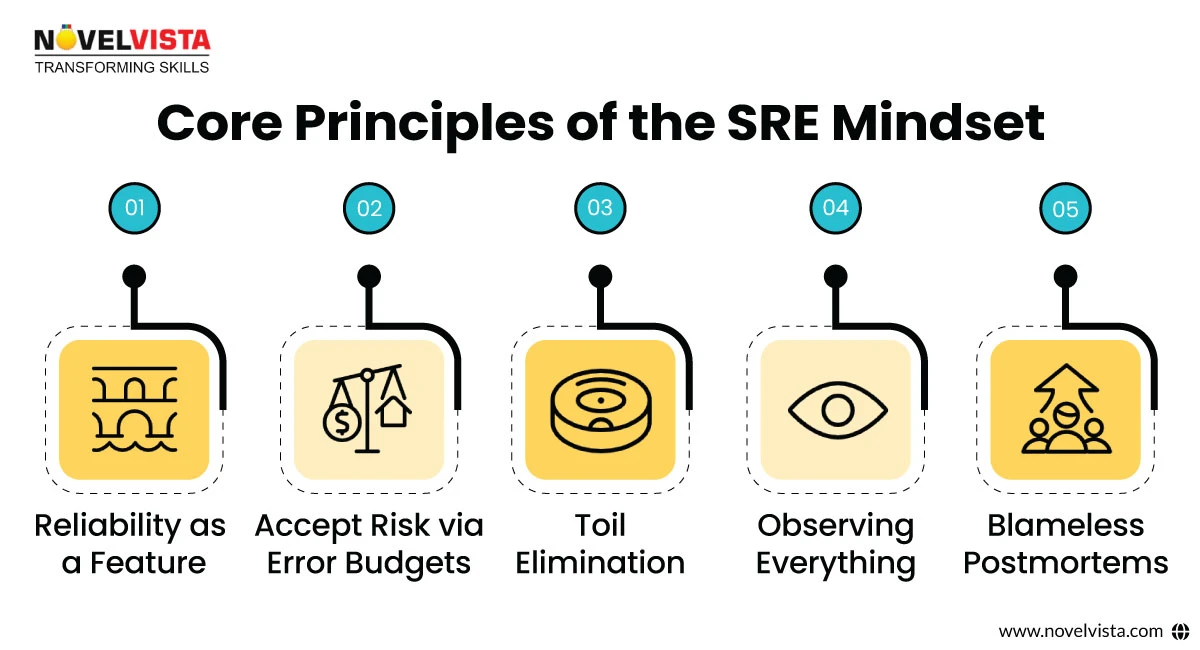
Selecting the SRE model isn’t just a technical transformation—it’s a cultural one. The SRE mindset changes the focus from reactive firefighting to proactive resilience. This cultural evolution is built around a few key principles:
When these principles are accepted, the results are clear: faster development cycles, fewer outages, and more reliable user experiences.
Choosing the right tools is critical for enabling scalable reliability. Here are some widely used SRE tools that help teams stay on top of their infrastructure:
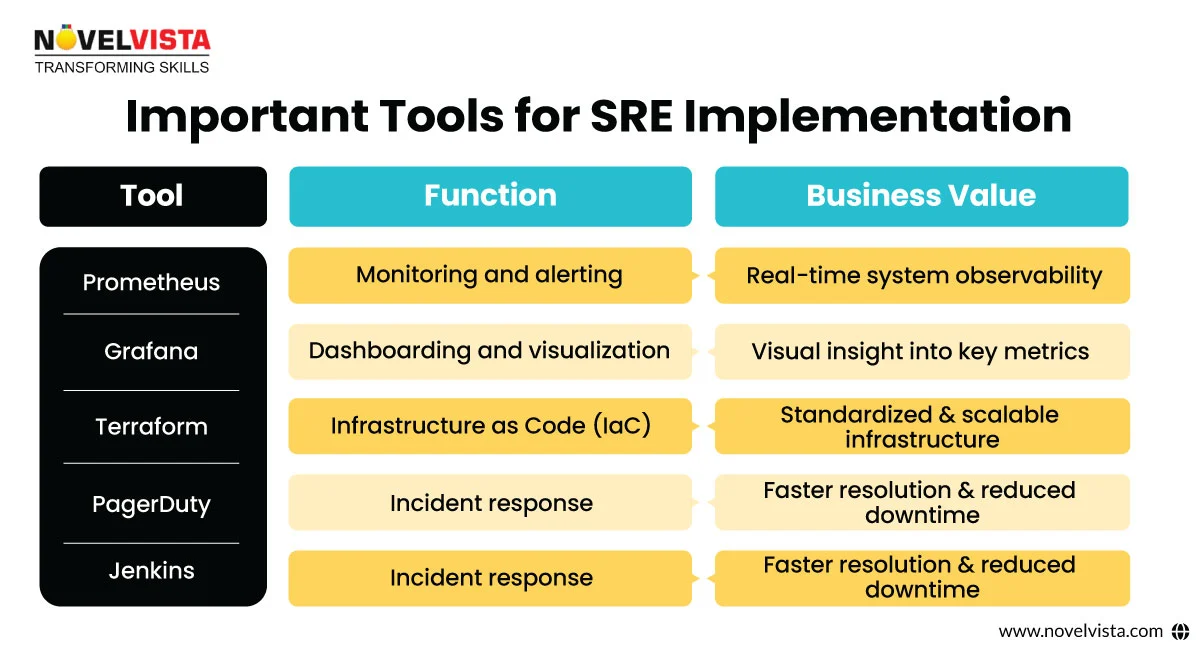
When combined, these SRE automation tools create an ecosystem that allows teams to act fast, detect issues early, and recover quickly—supporting long-term operational excellence.
For a comprehensive guide to the most impactful SRE tools and how to use them, explore our full article on SRE tools and best practices.
While SRE and DevOps share similar goals—namely, better collaboration, faster releases, and dependable systems—their methods vary in a few meaningful ways.
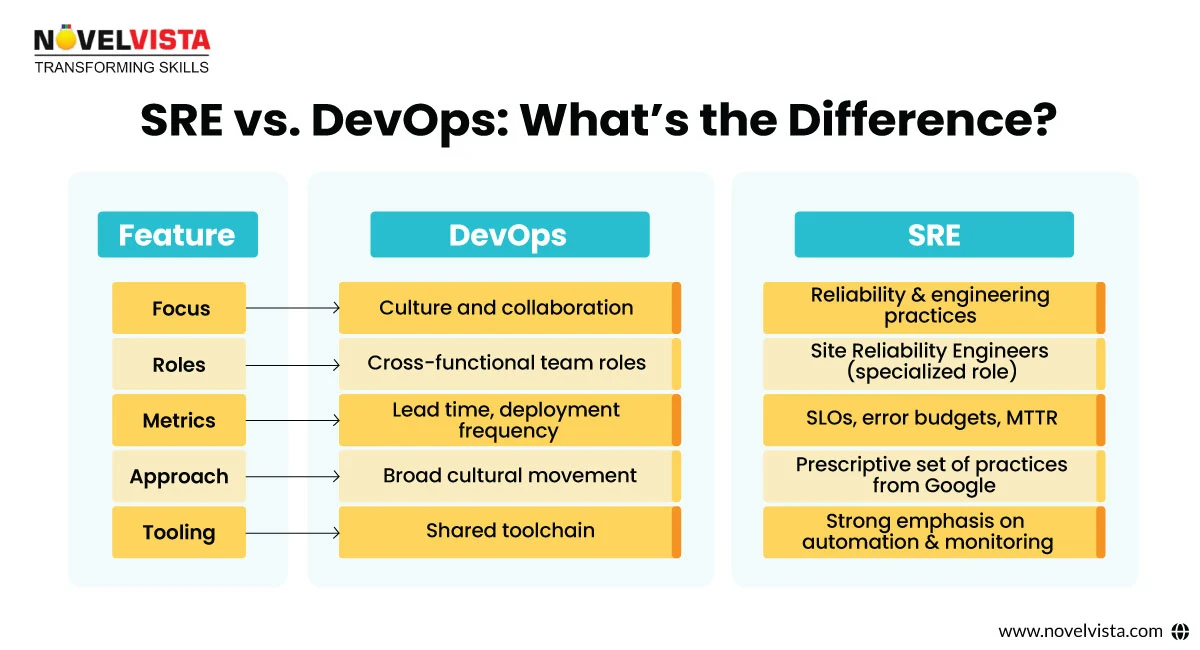
When should your business choose SRE over DevOps?
Want a deeper dive? Check out this Difference between SRE and DevOps.
As you use SRE, it helps to know where you stand. The SRE Maturity Model outlines the evolution of SRE practices from ad hoc to advanced:
The goal is not just to adopt tools, but to integrate SRE best practices into people, processes, and culture. Learn more about SRE best practices.
Site Reliability Engineering (SRE) transforms how organizations manage systems by combining engineering, automation, and operations. With the right SRE model, clear SLOs, error budgets, and a blameless culture, teams can improve reliability, reduce downtime, and accelerate development. SRE Certification is not just a practice, it’s a cultural and technical shift that aligns IT with business goals, driving operational excellence, scalability, and long-term growth.
Ready to put SRE principles into practice? Enroll in NovelVista’s SRE Foundation Certification to gain in-depth knowledge of SLOs, error budgets, automation, and monitoring. This course equips professionals with the skills to implement SRE models effectively, boost system reliability, and drive operational excellence. Take the next step in your career, master SRE best practices and become a trusted reliability expert in your organization.
SRE thrives on data. If you can’t measure it, you can’t improve it. Here are some key KPIs that successful organizations track:
Organizations that have adopted an effective SRE strategy often report:
These aren’t just numbers—they’re the outcomes of a mindset rooted in metrics and engineering excellence.

Author Details

Confused About Certification?
Get Free Consultation Call
Stay ahead of the curve by tapping into the latest emerging trends and transforming your subscription into a powerful resource. Maximize every feature, unlock exclusive benefits, and ensure you're always one step ahead in your journey to success.


