Category | DevOps
Last Updated On 17/02/2026

Most reliability issues today don’t come from a lack of monitoring. They come from overload, too many alerts, too many manual tasks, and too little time to think clearly. That’s why SRE solutions are no longer optional for modern engineering teams. They exist to reduce toil, protect uptime, and help teams scale reliability without burning out engineers.
In our SRE training programs, we regularly see teams overwhelmed not by outages, but by alert noise and manual recovery work. Organizations that adopt structured SRE solutions typically reduce on-call pressure before they improve uptime metrics.
This blog breaks down how SRE solutions work in real environments, how automation and AI fit together, which tools matter most, and how teams can adopt them step by step without overcomplicating operations.
Area |
Key Takeaway |
Problem |
Manual ops and alert overload don’t scale |
Core Idea |
SRE applies engineering to reliability |
Automation |
CI/CD, IaC, observability, incident automation, reduce toil |
AI Role |
Predictive alerts, noise reduction, self-healing |
Tools |
Terraform, Kubernetes, Datadog, PagerDuty, Cast AI |
Outcome |
Faster recovery, fewer errors, less on-call fatigue |
Reliability teams today manage systems that never sleep. Traffic spikes at odd hours, releases happen daily, and a single failure can ripple across services. Traditional operations struggle in this setup because they rely heavily on manual work and reactive fixes.
At its core, SRE applies software engineering principles to operations, so systems become more stable as they grow, not more fragile.
Traditional operations often work in firefighting mode. Something breaks, someone reacts, and the cycle repeats. This approach doesn’t scale when systems become distributed, cloud-based, and highly interconnected.
Automation, observability, and feedback loops work together so reliability improves over time, not just during outages. Across real production environments, teams moving from reactive operations to SRE models usually see fewer repeat incidents within the first few release cycles.
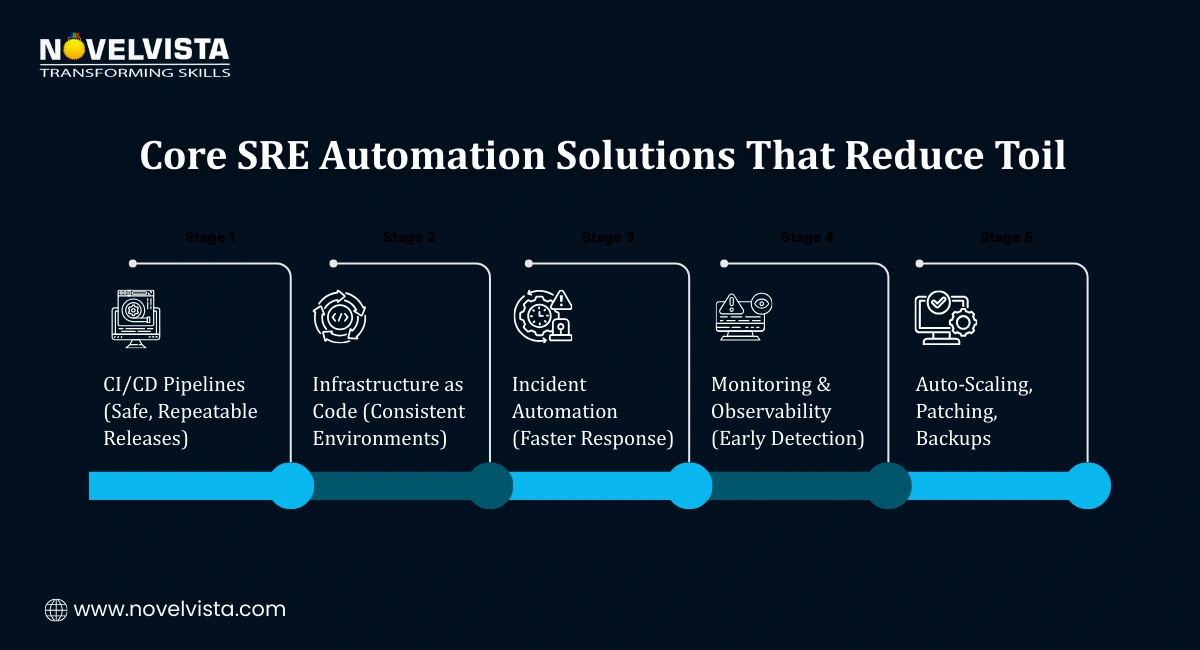
Before AI enters the picture, strong automation forms the foundation. These SRE automation solutions handle the repetitive work that drains engineering time and focus.
Tools like Jenkins and GitLab CI automate builds, tests, and deployments. This reduces human error and ensures releases are consistent, repeatable, and easier to roll back when needed.
Terraform and Ansible allow teams to define infrastructure in code. This makes environments predictable, version-controlled, and easier to scale or recover during incidents.
PagerDuty and Opsgenie automate alert routing, escalation paths, and response playbooks. Engineers get the right alert at the right time, cutting down Mean Time to Recovery (MTTR).
Prometheus, Grafana, and Datadog provide real-time visibility into system health. Instead of guessing, teams can see trends, detect early warning signs, and act before failures escalate.
Auto-patching, automated backups, and Kubernetes auto-scaling keep systems stable without constant manual effort. These automation layers ensure reliability doesn’t depend on heroics.
To see how engineering teams cut repetitive work and improve reliability, explore our guide on Proven Strategies to Reduce Toil in SRE.Step-by-step executive plan to integrate AI into SRE workflows
Practical KPIs to measure reliability, automation impact, and ROI
Clear maturity milestones to move from experimentation to operational excellence
Automation handles known tasks. AI handles complexity. This is where modern SRE tech solutions start to change how reliability teams work.
AI enhances traditional automation through AIOps by adding intelligence on top of raw data.
Teams adopting AI for reliability often struggle initially with trust and explainability. The strongest results come when AI augments existing SRE workflows instead of replacing human judgment. AI-driven SRE tech solutions help teams manage scale without losing control.
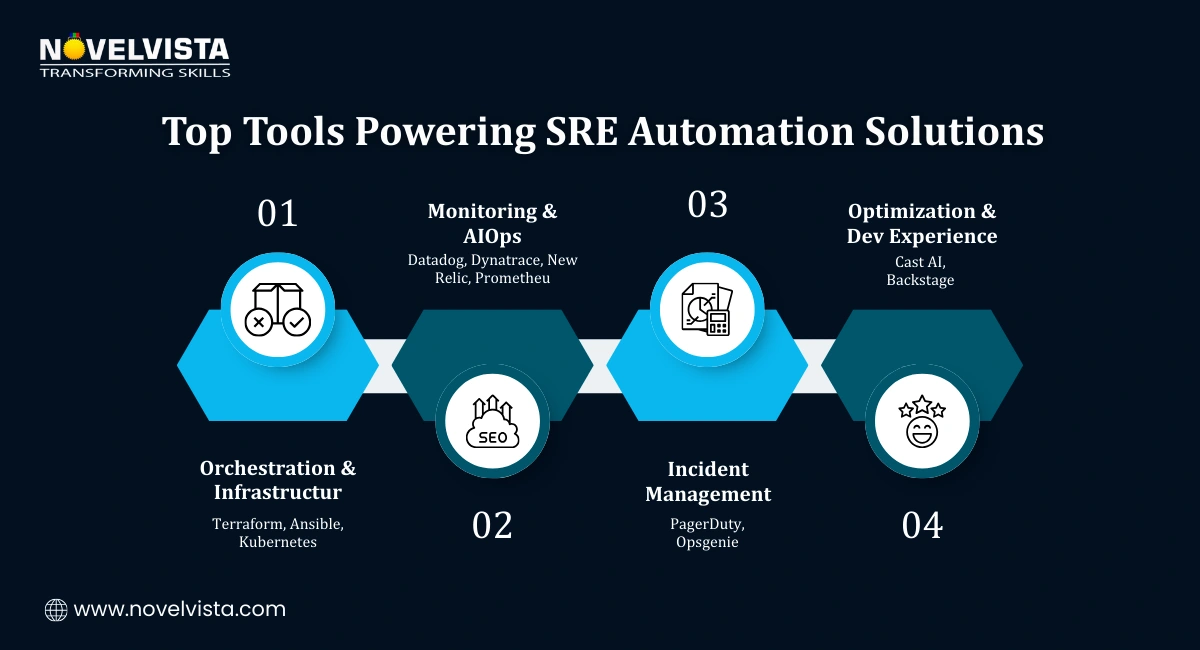
To make all this work, teams rely on a well-chosen toolset. These tools support different layers of SRE without overlap or confusion.
Orchestration and Infrastructure
They manage configuration, provisioning, and auto-scaling so infrastructure behaves consistently across environments.
Monitoring and AIOps
They provide deep observability, AI-powered insights, and proactive alerts that reduce guesswork.
Incident Management
They handle automated escalation, on-call schedules, and runbook execution during incidents.
Optimization and Developer Experience
They align cost, performance, and reliability while giving developers self-service access through internal platforms.
For a deeper look at how automation transforms reliability operations, read our Ultimate Guide to SRE Automation: SRE Monitoring Tools & Technologies.
This is one of the most common questions teams ask when they start investing seriously in reliability tooling. The honest answer is simple: there is no single “best” tool for everyone. The right choice depends on system size, cloud maturity, and how advanced your SRE practice already is.
Here’s how leading providers compare in real environments:
Dynatrace is known for full-stack AI-driven observability. Its strength lies in automatic root-cause analysis across applications, infrastructure, and user experience.
Datadog stands out for ease of use and fast onboarding. Its AI features, including Bits AI, help reduce alert noise and improve on-call experience.
Cast AI focuses on Kubernetes environments, combining cost optimization with reliability goals.
Key takeaway:
When people ask which company offers the best AI SRE solutions, the answer depends on scale, tech stack, and maturity. The smartest teams choose tools that fit their reliability goals, not just feature lists.
In real environments, teams rarely standardize on a single vendor. Most successful SRE setups combine multiple tools based on system complexity and operational maturity.
Buying tools is easy. Making them work is where teams struggle. These best practices help teams get real value from SRE solutions, not just dashboards.
These habits ensure SRE becomes part of daily work, not just an emergency response.
Teams don’t need to transform everything overnight. A phased approach works better and causes less disruption.
This roadmap helps teams adopt SRE automation solutions without overwhelming engineers or slowing delivery.
When implemented correctly, AI-driven reliability tooling delivers clear and measurable outcomes.
These outcomes show why mature organizations treat SRE tech solutions as core infrastructure, not optional add-ons.
Modern systems need more than basic monitoring. They need reliability that is designed, measured, and improved continuously. SRE solutions, supported by automation and AI, give teams the structure and tools needed to handle scale without burning out engineers.
These practices reflect common patterns observed across cloud-native, enterprise, and regulated environments where SRE principles are applied at scale.
When teams combine strong SRE automation solutions with intelligent SRE tech solutions, they gain faster recovery, better stability, and long-term operational confidence.
If you want to understand SRE beyond tools and build real reliability skills, NovelVista’s SRE Foundation and Practitioner Certification Training is a strong next step. The program covers SRE principles, automation practices, SLOs, error budgets, and real-world reliability scenarios. It’s designed for engineers, DevOps professionals, and IT leaders who want practical knowledge they can apply immediately in modern production environments.

Author Details

Confused About Certification?
Get Free Consultation Call
Stay ahead of the curve by tapping into the latest emerging trends and transforming your subscription into a powerful resource. Maximize every feature, unlock exclusive benefits, and ensure you're always one step ahead in your journey to success.


