Category | DevOps
Last Updated On 05/11/2025

Your system’s stable, but your SREs are exhausted. They’re stuck firefighting issues instead of building better systems. That hidden workload? It’s SRE toil, and it’s time to fix it. In simple terms, SRE toil is the repetitive, manual work that scales with your services but adds no lasting value. From restarting servers to handling the same alerts repeatedly, toil consumes engineering time that could be spent improving systems or designing new features.
This blog walks you through what toil SRE really looks like, how it affects your team and business, and proven strategies for SRE toil reduction. You’ll also learn how to measure it, the tools that make automation easier, and real-life case studies that show the difference automation can make.
The strategies in this blog align with Google’s SRE principles, widely recognized as industry standards for operational reliability. Google recommends keeping toil below 50% of engineering time, a benchmark adopted by leading tech organizations globally. Following these best practices ensures that your SRE efforts meet industry-proven methodologies.
Not all work is equal. In SRE, toil is a specific type of work that drains teams without producing long-term benefits. Here’s what defines it:
1. Manual: Tasks that require human intervention but could be automated.
2. Repetitive: Tasks done often with little variation.
3. Automatable: Tasks that could be scripted or systemized but remain manual.
4. Tactical: Quick fixes that don’t solve the underlying problem.
5. No Enduring Value: Once completed, the task doesn’t contribute to lasting improvements.
6. Scales with Service Growth (O(n)): As systems grow, toil grows linearly or exponentially, making it impossible to manage manually.
In short, SRE toil grows as your services grow. The only sustainable way to tackle it is through thoughtful automation and process improvement.
SRE toil isn’t just a time sink — it affects reliability, morale, and business outcomes. Here’s how:
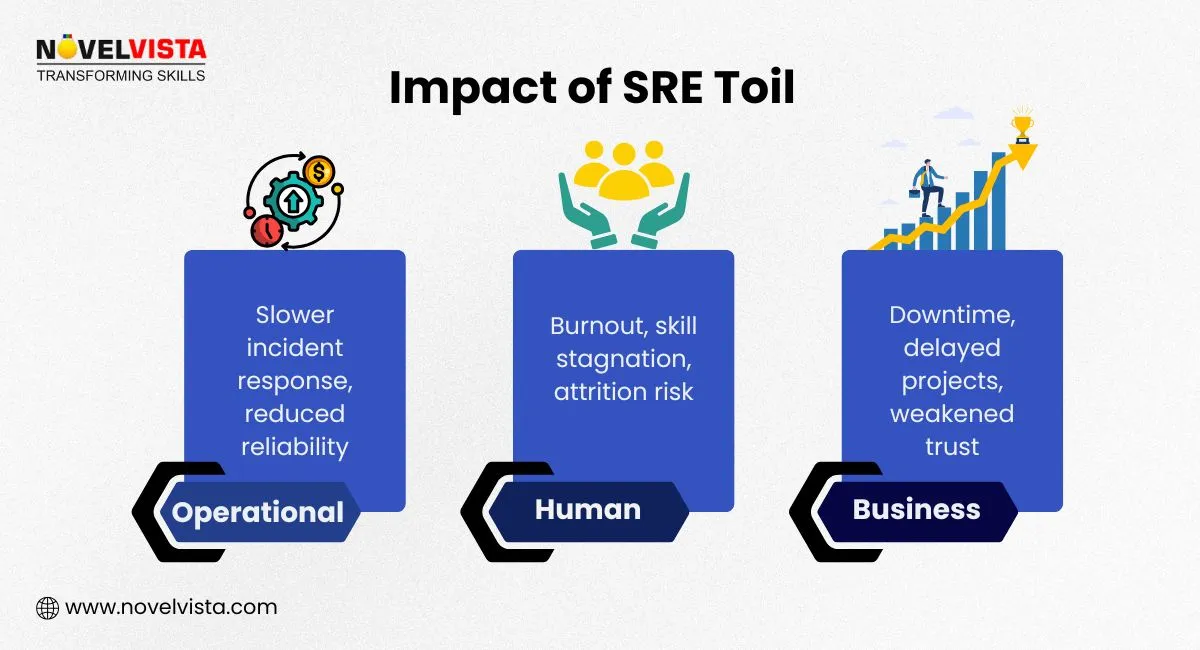
Cut the busywork and boost innovation.
Learn proven strategies to measure, automate, and
eliminate toil in your SRE workflows.
Tracking and measuring toil is essential for effective SRE toil reduction. Google recommends keeping toil below 50% of total engineering work. Here’s how to do it:
Reducing toil SRE requires focused automation and process improvement. Key strategies include:
By applying these strategies, teams can reduce SRE toil, improve reliability, accelerate deployments, and free up engineers to work on high-value initiatives.
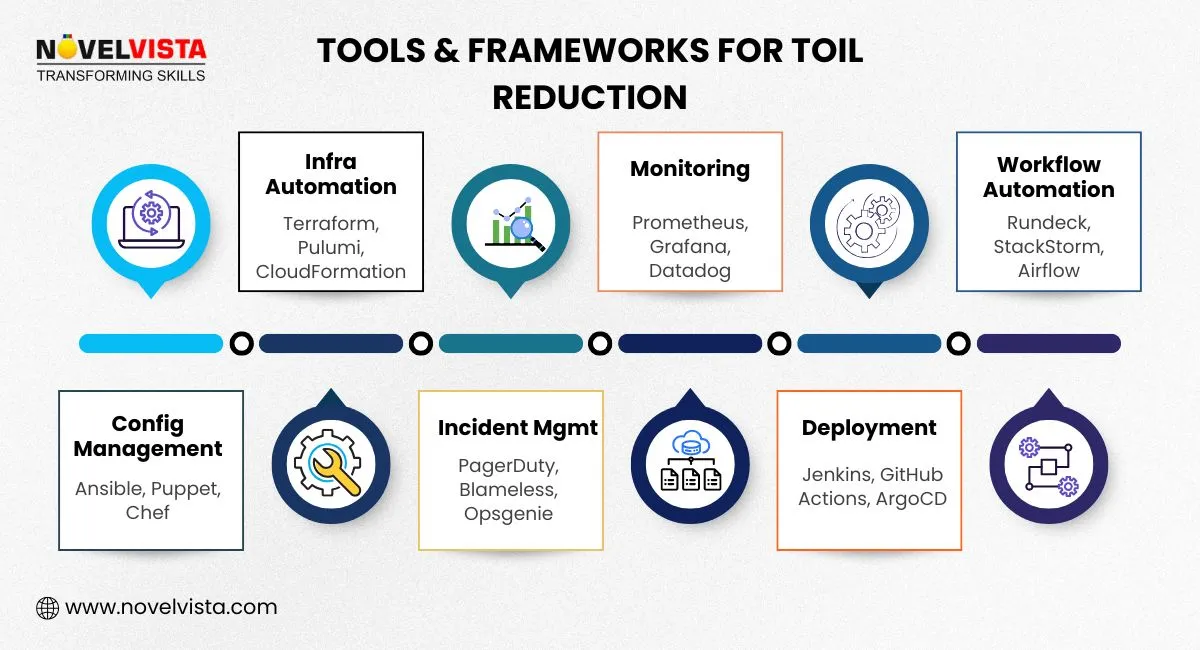
Choosing the right tools makes SRE toil reduction practical and measurable. Key categories include:
Reducing SRE toil brings measurable advantages for both organizations and professionals:
Sustainable SRE toil reduction requires a strategic approach:
Tracking metrics ensures SRE toil reduction efforts are effective:
Google engineers faced a rising manual workload in datacenter maintenance, especially in repairing failed network line cards. As infrastructure scaled, repetitive “drain-repair-undrain” tasks created human errors and operational delays.
To solve this, Google built automated repair systems that:
With the Jupiter fabric, automation became smarter, handling reboots, verifications, and hardware installs automatically. This cut toil drastically, reduced downtime, and freed engineers for innovation.
Key Takeaways:
(Source: Google SRE)
Case Study 2: Decommissioning Filer-Backed Home Directories
Summary:
Google’s Corp Data Storage (CDS) SRE team eliminated operational toil by decommissioning legacy filer-backed home directories used for over 14 years.
Toil Reduction Strategies:
Challenge:
Legacy NFS/CIFS filers were expensive, latency-prone, and incompatible with Google’s BeyondCorp security model. Managing shares, access, and troubleshooting created heavy toil for CDS engineers.
Solution:
The team launched Project Moira, an iterative, multi-phase migration from filers to modern tools like Google Drive, Team Drive, Cloud Storage, Piper, and internal systems. Key enablers included:
Impact:
Key Lessons:
(Source: Google SRE)
Reducing SRE toil is not just about automation; it’s about creating scalable reliability and freeing engineers to focus on innovation. Effective toil reduction improves system stability, team morale, and overall business performance. Organizations benefit from faster deployments, fewer incidents, and stronger operational alignment, while SRE professionals gain meaningful work and clear career growth.
Take control of toil in your systems. Enroll in NovelVista’s SRE Foundation Training or SRE Practitioner Certification to master practical SRE toil reduction techniques, automation strategies, and industry best practices. Build systems that work smarter, not harder.

Author Details

Confused About Certification?
Get Free Consultation Call
Stay ahead of the curve by tapping into the latest emerging trends and transforming your subscription into a powerful resource. Maximize every feature, unlock exclusive benefits, and ensure you're always one step ahead in your journey to success.


