Category | DevOps
Last Updated On 09/04/2026

In modern distributed systems, even a minor latency spike or cascading failure can trigger massive service disruptions impacting SLAs, user experience, and ultimately, revenue. According to industry estimates, a single hour of downtime can cost businesses anywhere from $100,000 to over $1 million, depending on scale and sector. In 2026, downtime isn’t just a technical failure it’s a “Velocity Killer.” Every hour your engineering team spends firefighting production issues is an hour stolen from AI innovation, product development, and strategic initiatives that drive competitive advantage.
This raises a critical architectural and operational question:
Should you invest in building a full-scale in-house SRE team or adopt a more scalable, outcome-driven approach like SRE as a Service?
For CTOs, DevOps leaders, platform engineers, and IT decision-makers navigating complex infrastructure, the challenge isn’t just maintaining uptime it’s about maximizing Engineering Velocity while ensuring reliability at scale. Hiring experienced SREs with expertise in observability, incident management, and automation is not only time-consuming but also significantly expensive in today’s competitive talent market.
This is where SRE as a Service emerges as a strategic alternative. By leveraging specialized site reliability engineering SRE services through SRE outsourcing services, organizations can embed reliability engineering practices such as SLO-driven monitoring, error budget management, and automated incident response without the overhead of building and scaling an in-house team.
Let’s dive into how SRE as a Service is redefining reliability engineering and why more organizations are turning to SRE outsourcing to build resilient, high-performing systems while accelerating innovation.
SRE as a Service is a delivery model where organizations outsource their site reliability engineering needs to specialized providers instead of building an in-house team.
These providers offer end-to-end site reliability engineering SRE services, including:
Unlike traditional hiring, where you onboard full-time engineers, SRE outsourcing services give you access to a ready-made team of experts who can start delivering value immediately.
This approach blends the principles of DevOps, automation, and reliability engineering without the overhead of recruitment and training.
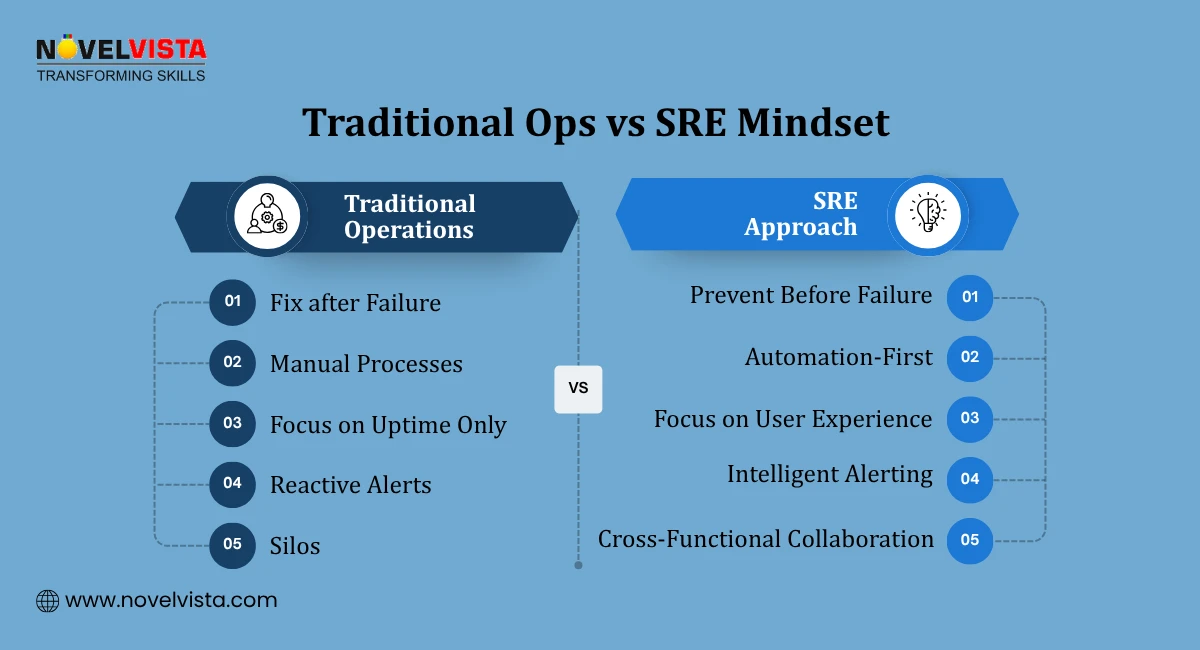
The shift toward SRE outsourcing is not accidental it’s driven by real challenges organizations face today.
Experienced SREs with deep expertise in distributed systems, observability (metrics, logs, traces), and incident management are scarce. Finding engineers who can design SLO-driven architectures, manage error budgets, and implement reliable CI/CD pipelines often takes months if not longer.
A full-time SRE involves more than just salary it includes costs for observability tools (APM, monitoring, alerting), infrastructure, training, and 24/7 on-call rotations.
In 2026, SRE salaries are significant: $120,000–$200,000+ annually in the U.S. and ₹8–₹21 LPA+ in India, depending on experience. When combined with tooling and operational overhead, building an in-house team that achieves SRE as a Service-level maturity requires substantial ongoing investment.
With SRE outsourcing services, teams come pre-equipped with standardized playbooks, automation frameworks, and production-grade observability stacks. This enables immediate rollout of reliability practices like SLI/SLO tracking, incident response automation, and performance optimization without long onboarding cycles.
Modern systems experience variable workloads, especially in cloud-native and microservices environments. SRE outsourcing allows dynamic scaling of reliability operations whether it’s handling peak traffic events, managing incident surges, or optimizing resource utilization without over-provisioning internal teams.
Adopting SRE as a Service offers several strategic advantages that go beyond cost savings.
Proactive monitoring and automated alerting systems ensure issues are detected and resolved before they escalate.
Expert teams continuously optimize system performance using industry best practices.
Unlike in-house teams, site reliability engineering SRE services provide round-the-clock support.
You gain access to a diverse pool of specialists with experience across industries and technologies.
With predefined playbooks and automation, SRE outsourcing services reduce mean time to resolution (MTTR).
Here’s a quick comparison to help you understand the difference:
Factor | SRE as a Service | Full-Time SRE Hiring |
Cost | Predictable, lower | High salaries + overhead |
Hiring Time | Immediate | Months |
Expertise | Diverse team | Limited to hired individuals |
Scalability | Flexible | Difficult to scale quickly |
Availability | 24/7 | Limited to working hours |
For organizations aiming for agility, SRE as a Service clearly provides a competitive edge. SRE Pillars help organizations build resilient systems through observability, automation, incident response, and continuous improvement.
Not every organization needs a full in-house team. Here are some scenarios where SRE outsourcing services make perfect sense:
Startups need reliability but can’t afford large engineering teams.
During migration, expert guidance ensures minimal disruption.
If outages are impacting customer experience, SRE outsourcing can stabilize operations.
If your team lacks SRE skills, outsourcing bridges the gap instantly.
Choosing the right provider is critical to success. Here’s what you should evaluate:
Ensure the provider clearly defines service level agreements and objectives.
Look for capabilities like real-time monitoring, observability, and predictive analytics.
Check case studies and industry expertise in delivering site reliability engineering SRE services.
Automation is at the heart of SRE your provider should excel in it.
While SRE outsourcing services offer numerous benefits, there are some challenges to consider.
Working with external teams can lead to misalignment.
Solution: Establish clear communication channels and regular sync-ups.
Sharing infrastructure access can raise security issues.
Solution: Choose providers with strong compliance and security frameworks.
Aligning external teams with internal workflows can be tricky.
Solution: Use standardized tools and processes for smoother integration.
The future of site reliability engineering SRE services is being rapidly shaped by intelligent automation, AI-driven operations, and deeper integration with modern engineering ecosystems.
AI-powered observability platforms are enabling predictive issue detection, anomaly identification, and root cause analysis often before users are impacted.
The next evolution is Agentic AI SRE workflows, where autonomous agents can detect incidents, trigger remediation playbooks, and continuously optimize system performance with minimal human intervention significantly reducing MTTR and operational overhead.
From CI/CD pipelines to incident response and infrastructure scaling, automation will continue to eliminate repetitive manual tasks and improve system resilience.
SRE is increasingly becoming a core layer within platform engineering, embedding reliability directly into developer workflows and self-service infrastructure platforms.
Emerging standards like Model Context Protocol (MCP) are enabling better context sharing between AI systems and infrastructure tools, allowing more accurate decision-making, intelligent automation, and seamless coordination across complex environments.
Future SRE as a Service models will go beyond uptime aligning reliability directly with business KPIs such as revenue impact, customer experience, and Engineering Velocity.
The SRE Framework provides a structured approach to managing reliability through SLOs, automation, monitoring, and continuous improvement.
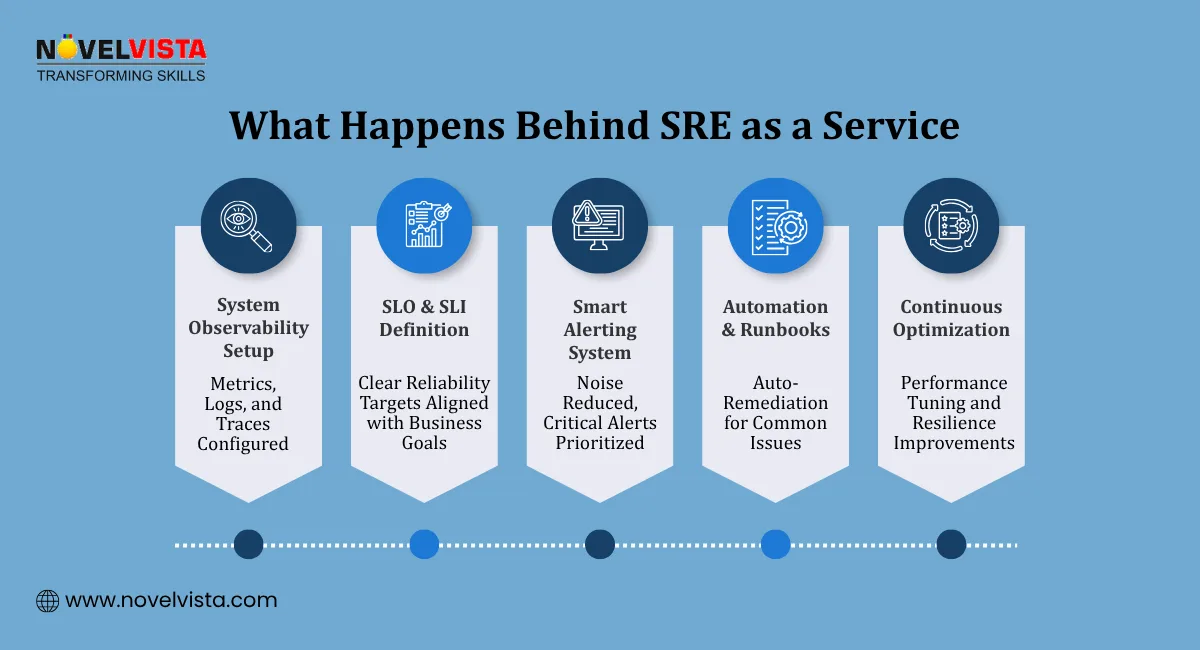
In highly distributed, cloud-native environments, reliability is no longer just about uptime it’s about consistently meeting SLOs, managing error budgets, and ensuring seamless user experiences under unpredictable load conditions. Even minor disruptions can cascade across services, directly impacting revenue, customer trust, and operational stability.
While building an in-house team might appear to be the conventional path, it often introduces challenges around hiring specialized talent, managing on-call fatigue, and maintaining a mature observability and automation stack. Achieving true reliability engineering maturity internally requires sustained investment in both people and tooling.
This is where SRE as a Service provides a more strategic and execution-ready alternative. By leveraging specialized site reliability engineering SRE services through SRE outsourcing services, organizations can operationalize best practices such as SLI/SLO-driven monitoring, automated incident response, and continuous performance optimization without the friction of building everything from scratch.
Whether you’re a high-growth startup dealing with scaling bottlenecks or an enterprise modernizing legacy systems, SRE outsourcing enables you to build resilient, self-healing systems while optimizing cost, engineering efficiency, and time-to-reliability.
Ready to build reliable, scalable systems and advance your SRE expertise?
Join NovelVista’s SRE Foundation Training & Certification and gain hands-on knowledge of modern reliability practices, real-world incident management strategies, and industry-recognized skills. Designed for DevOps engineers, IT professionals, and aspiring SREs, this course helps you master SLOs, SLIs, automation, and proactive reliability engineering in today’s cloud-native environments.
Start your SRE journey with confidence today!

Author Details

Confused About Certification?
Get Free Consultation Call
Stay ahead of the curve by tapping into the latest emerging trends and transforming your subscription into a powerful resource. Maximize every feature, unlock exclusive benefits, and ensure you're always one step ahead in your journey to success.


