Category | DevOps
Last Updated On 07/02/2026

Systems don’t fail because teams don’t work hard. They fail because scale, speed, and complexity grow faster than reliability practices. That gap is exactly where SRE in Cloud steps in.
In SRE training programs, many professionals share that reliability issues only became visible after moving to cloud-native architectures, where scale exposed weaknesses in manual operations and reactive monitoring.
As organizations move deeper into AWS, Azure, and GCP, reliability can no longer be handled with manual fixes or reactive monitoring. Modern cloud environments demand engineers who can treat reliability as an engineering problem, not an operational afterthought. This is why the role of the cloud site reliability engineer has become so important.
This blog explains what SRE in Cloud really means, what cloud reliability engineers actually do, the skills they need, and how the career path unfolds in real-world environments.
Topic |
What You’ll Learn |
SRE in Cloud |
How reliability is engineered in cloud systems |
Key Role |
What a cloud site reliability engineer actually does |
Core Skills |
Coding, cloud platforms, automation, observability |
Career Path |
How professionals grow into senior SRE roles |
Business Value |
Why organizations rely on SRE cloud practices |
A cloud site reliability engineer sits between development and operations, but the role is not a compromise; it’s a discipline of its own.
On a daily basis, an SRE cloud engineer focuses on three core goals:
Rather than chasing uptime alone, SRE in Cloud teams use Service Level Objectives (SLOs) and error budgets. These tools help balance speed and stability, allowing teams to release faster without breaking reliability.
This is what separates a cloud reliability engineer from a traditional operations role, decisions are driven by measurable reliability targets, not gut feeling.
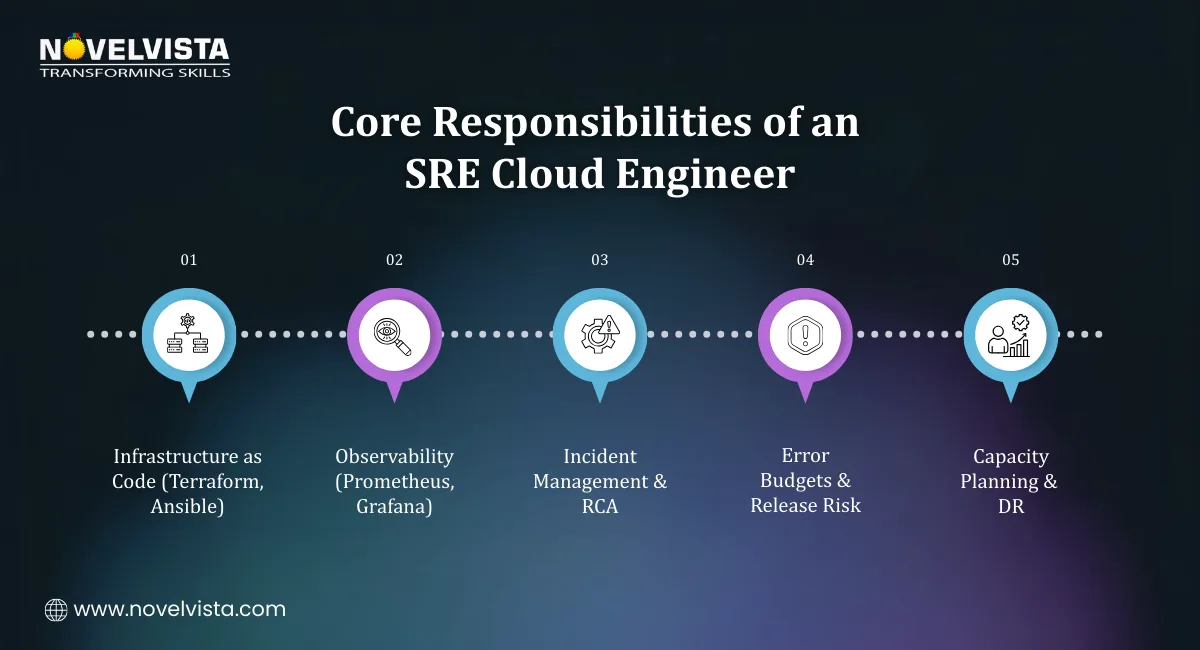
The responsibilities of an SRE cloud engineer are broad, but they all connect back to reliability and scale.
Cloud reliability engineers design systems that can grow and fail safely. This often includes:
Infrastructure isn’t just deployed, it’s engineered to handle failure.
In SRE in Cloud, visibility comes before control. Engineers build deep observability using:
Good monitoring helps teams see issues early and respond calmly.
When things break, the cloud site reliability engineer often leads:
The goal isn’t blame, it’s learning and prevention.
SRE cloud practices use error budgets to decide:
Error budgets are widely adopted in mature SRE organizations as a governance mechanism that balances innovation speed with service reliability. This keeps development fast without sacrificing stability.
Cloud reliability engineers plan for the worst so users rarely feel it:
Modern SRE cloud practices emphasize designing for failure, assuming components will break, and building systems that recover automatically without human intervention.
Traditional operations focus on keeping systems running. SRE in Cloud focuses on designing systems that keep themselves running.
A cloud reliability engineer doesn’t wait for incidents to happen. They look at patterns, risks, and bottlenecks long before users notice issues.
This mindset is what makes SRE cloud roles so valuable in modern cloud environments.
Being effective in SRE in Cloud is less about knowing one tool and more about building the right mix of engineering, cloud, and people skills. A strong cloud reliability engineer usually grows these capabilities over time.
SRE cloud engineers write code regularly, not occasionally. Programming is used to remove toil, automate fixes, and build internal tools. Common languages include:
The goal isn’t to become a software architect, but to think like an engineer who solves operational problems with code.
A cloud site reliability engineer needs deep hands-on experience with at least one major cloud platform:
This knowledge helps SRE in Cloud teams design systems that use cloud-native resilience instead of fighting the platform.
Modern cloud reliability engineer roles almost always involve:
Understanding how workloads behave inside clusters is key to maintaining reliability at scale.
SRE cloud engineers work closely with delivery pipelines and monitoring stacks:
Good SRE in Cloud practices rely on data, not assumptions.
Technical skills alone are not enough. A cloud reliability engineer must:
Strong SRE engineers typically develop skills incrementally, combining cloud platform knowledge with automation and observability rather than mastering tools in isolation.
For sustained growth in reliability roles, explore more about how SRE skills support career progression and prepare professionals for higher-impact responsibilities.
Many roles sound similar, but the focus of SRE in Cloud is distinct.
Role |
Primary Focus |
How It Differs |
Cloud Engineer |
Provisioning infrastructure |
Less focus on live service reliability |
DevOps Engineer |
CI/CD and delivery workflows |
SRE cloud engineer prioritizes production stability |
Cloud Reliability Engineer |
Reliability and automation |
Deep engineering approach to operations |
The key difference is intent. A cloud site reliability engineer is measured by reliability outcomes, not just deployment speed or infrastructure uptime.
The career path in SRE in Cloud is practical and impact-driven.
Many start with:
At this stage, learning automation and cloud fundamentals is the priority.
Professionals move into dedicated SRE cloud roles:
Impact starts to matter more than years of experience.
Senior cloud reliability engineers often:
Growth comes from reducing incidents, cutting toil, and improving system behavior, not just managing bigger teams.
Effective SRE in Cloud teams relies on proven practices, not heroics.
These practices help cloud reliability engineers stay proactive instead of reactive.
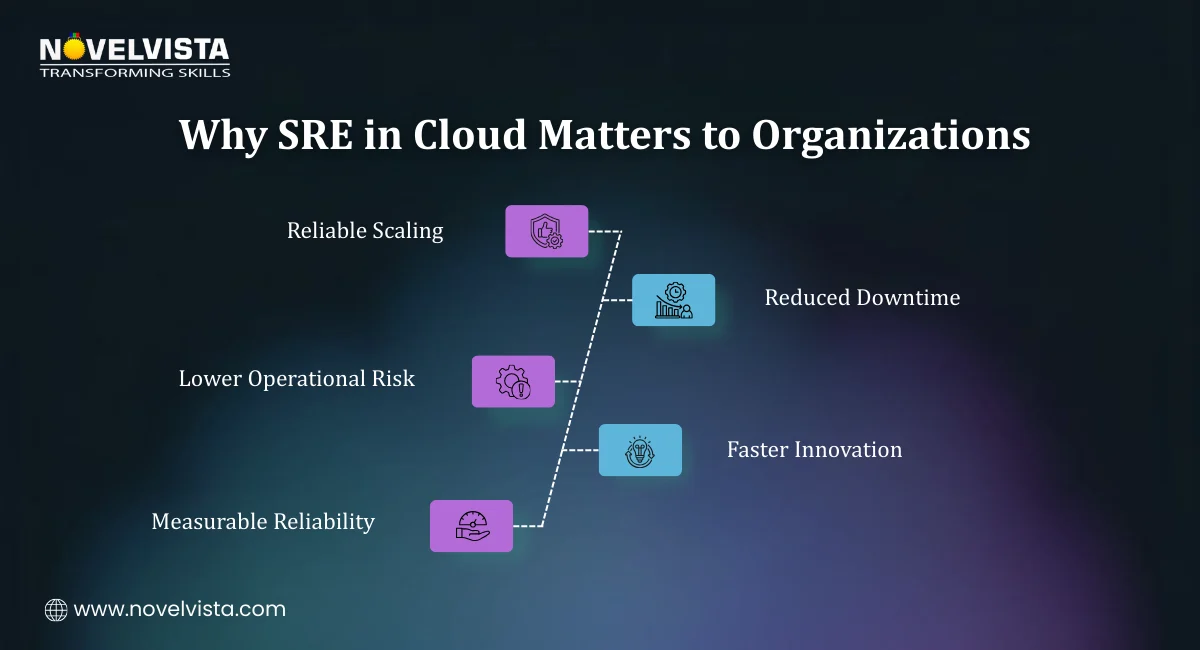
Organizations adopt SRE in Cloud because it solves real business problems:
SRE principles are increasingly referenced in cloud architecture best practices as a way to align engineering teams around shared reliability goals.
SRE in Cloud has become essential as cloud systems grow more complex and always-on. Reliability today needs engineering, automation, and clear measurement, not manual fixes. That is where cloud site reliability engineers make a real difference.
Treating reliability as an engineering discipline rather than a support function leads to more stable systems and healthier engineering teams over time.
By using SLOs, error budgets, and automation, SRE cloud engineers reduce downtime and prevent repeat incidents. For professionals, a cloud reliability engineer role offers strong demand, long-term growth, and hands-on impact as cloud adoption continues to expand.

Author Details

Confused About Certification?
Get Free Consultation Call
Stay ahead of the curve by tapping into the latest emerging trends and transforming your subscription into a powerful resource. Maximize every feature, unlock exclusive benefits, and ensure you're always one step ahead in your journey to success.


