Category | Quality Management
Last Updated On 04/03/2026

Did you know that the average cost of IT downtime can range from thousands to millions of dollars per hour depending on the industry? Studies show that a single critical IT outage can disrupt operations, damage customer trust, and impact brand reputation within minutes.
Now ask yourself:
What happens if your customer portal goes down for 3 hours?
What if a failed system update crashes your production environment?
What if your service desk cannot respond during peak business hours?
These are not rare situations. They are examples of common IT service failures that organizations experience every day.
Whether you are an IT manager, service desk professional, CIO, operations head, or business leader, understanding common IT service failures is essential. In today’s digital-first world, IT is not just support it is the backbone of revenue, customer experience, and competitive advantage.
This blog will explore the most frequent IT service failures, their root causes, and practical strategies to avoid them using strong IT service management practices.
Before we discuss solutions, we need clarity.
Common IT service failures refer to recurring breakdowns in IT services that disrupt business operations, reduce service quality, or violate service level agreements (SLAs).
These may include:
System outages
Application crashes
Slow performance
Failed updates
Delayed incident resolution
Service desk overload
It is important to distinguish between simple technical glitches and broader IT service management failures.
A server crash is a technical issue.
Repeated crashes due to poor change control, lack of monitoring, or weak governance? That’s an IT service management failure.
The difference lies in process maturity.
When organizations lack structured ITSM frameworks, they experience recurring IT service failures that impact:
Business continuity
Customer satisfaction
Regulatory compliance
Operational efficiency
Let’s explore the most frequent types of IT service failures.
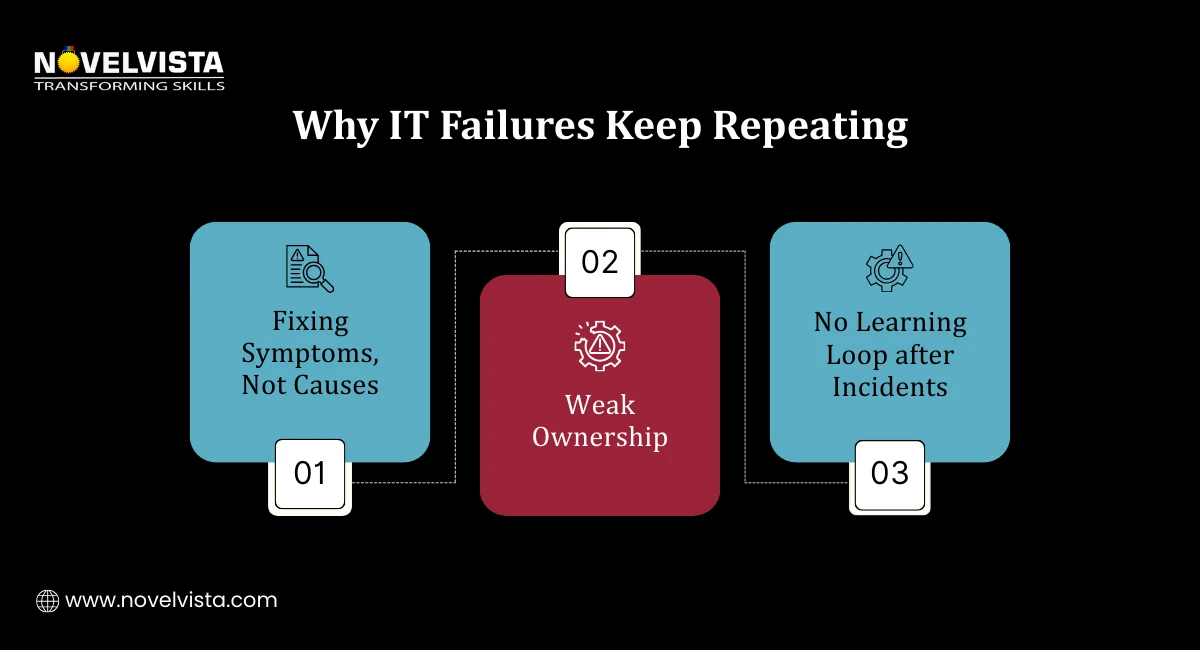
One of the most common IT service failures is delayed or ineffective incident handling.
Symptoms include:
Long resolution times
No clear ownership
Escalation confusion
Repeated similar incidents
Without defined incident workflows, IT teams react instead of respond strategically. This increases downtime and frustrates users.
Many IT service failures occur right after system updates or changes.
Unplanned downtime often results from:
Unauthorized changes
Lack of testing
Poor rollback planning
Incomplete impact assessment
Change-related IT service failures are particularly dangerous because they are preventable.
Strong change enablement practices reduce service disruptions significantly.
If incidents keep happening again and again, the root cause is not being addressed.
This is a classic example of IT service management failures.
Without proper problem management:
Temporary fixes become permanent habits
Technical debt increases
Productivity declines
Root cause analysis (RCA) must be systematic, not optional.
Many common IT service failures escalate because issues are detected too late.
Reactive IT environments rely on users to report problems.
Proactive environments use:
Real-time monitoring tools
Automated alerts
Performance dashboards
Predictive analytics
When monitoring is weak, minor performance degradation turns into major outages.
Even when technical resolution is fast, communication gaps create frustration.
Common communication issues:
No status updates
Inconsistent information
No clear timeline
Lack of post-incident reports
Communication failures amplify IT service failures in the eyes of stakeholders.
Now let’s dig deeper.

Why do these IT service failures keep happening?
Undefined workflows create confusion and increase the risk of common IT service failures. Without documented processes, teams rely heavily on individual knowledge rather than structured systems. When key employees leave, this dependency often leads to operational gaps, recurring IT service failures, and even broader IT service management failures that disrupt service stability.
Without IT governance frameworks like ITIL or ISO-based service standards, organizations often lack the structure needed to deliver consistent and reliable services, increasing the risk of IT service management failures. Strong governance establishes clear accountability, defined processes, and compliance controls, which play a critical role in preventing recurring common IT service failures and improving overall service stability.
Modern IT environments require expertise in:
Cloud platforms
Cybersecurity
Automation
DevOps
Service integration
Skill shortages increase dependency on trial-and-error fixes.
Using multiple disconnected tools leads to:
Data silos
Duplicate records
Inconsistent reporting
Integrated ITSM platforms reduce the risk of common IT service failures.
5. Absence of Continual Service Improvement
Many organizations focus on fixing immediate issues but fail to improve underlying systems, which increases the risk of recurring IT service failures. Without proper measurement, performance tracking, and continuous optimization, these disruptions gradually become normalized, leading to repeated common IT service failures and long-term IT service management failures. The ISO 20000 Cost Guide helps organizations understand certification expenses, implementation investments, and long-term ROI associated with building a compliant IT service management system.
Prevention is always more cost-effective than recovery.
Here’s how organizations can avoid common IT service failures.
Adopt a formal ITSM framework.
This ensures:
Defined processes
Clear ownership
SLA tracking
Audit readiness
Structured ITSM reduces IT service management failures significantly.
Key steps include:
Define severity levels
Establish escalation matrices
Perform root cause analysis
Maintain knowledge bases
This prevents recurring IT service failures and improves response times.
To avoid change-related IT service failures:
Conduct impact assessments
Use staging environments
Document rollback plans
Require change approvals
Controlled changes protect service stability.
Use monitoring tools that provide:
Real-time alerts
Performance insights
Automated ticket creation
Predictive analytics
Automation minimizes human error a major cause of IT service failures.
Track metrics such as:
Mean Time to Resolve (MTTR)
First Call Resolution (FCR)
Service availability percentage
Change success rate
Data-driven insights reduce common IT service failures.
IT must understand business priorities.
When IT strategy aligns with business objectives:
Risk exposure reduces
Service disruptions minimize
Investments deliver ROI
This strategic alignment prevents IT service management failures at scale.
Organizations that successfully avoid common IT service failures focus on building long-term resilience rather than just fixing problems as they arise. Instead of reacting to every outage, they invest strategically in risk management, business continuity planning, disaster recovery testing, capacity forecasting, and regular compliance audits. These practices help identify vulnerabilities before they turn into serious IT service failures. By strengthening governance and preparedness, they also minimize recurring IT service management failures that stem from weak processes or poor oversight. Most importantly, such organizations treat IT as a strategic enabler of growth and innovation not merely a support function. The real difference between reactive IT environments and resilient IT operations lies in preparation, planning, and proactive service management.
Common IT service failures are never truly random they are visible warning signs of deeper process gaps, weak governance, and ineffective management practices. The encouraging reality is that most IT service failures are entirely preventable with the right strategy and discipline. Organizations that implement structured IT service management, strengthen incident and change enablement processes, invest in proactive monitoring, and align IT initiatives with business objectives significantly reduce recurring IT service management failures.
In today’s digital economy, where customer experience and operational continuity define success, reliability is not a luxury it is a competitive differentiator. Preventing common IT service failures is no longer just an operational goal for IT teams; it is a strategic business imperative that directly impacts growth, reputation, and long-term resilience.

If you want to reduce common IT service failures and eliminate recurring IT service management failures, strengthening your ITSM expertise is essential.
Join NovelVista’s ISO/IEC 20000:2018 Lead Auditor Certification Training to gain practical auditing skills, real-world service management insights, and globally recognized credentials. This course equips you to assess service management systems, identify compliance gaps, and drive continual improvement with confidence.
Designed for IT leaders and ITSM professionals, it empowers you to build resilient frameworks that minimize risk and enhance service reliability.
Start your ISO 20000 auditor journey today and lead service excellence with confidence.
Author Details

Course Related To This blog
ISO 20000:2018 Lead Auditor
Confused About Certification?
Get Free Consultation Call
Stay ahead of the curve by tapping into the latest emerging trends and transforming your subscription into a powerful resource. Maximize every feature, unlock exclusive benefits, and ensure you're always one step ahead in your journey to success.


