Category | DevOps
Last Updated On 22/05/2026
This blog explains how to build and use an SRE Playbook for incident response, service reliability, escalation, communication, post-incident learning, and operational improvement. You will learn what a playbook includes, how teams respond during incidents, which metrics matter, and how a practical reliability workflow helps reduce downtime.
For modern DevOps, cloud, platform engineering, and IT operations teams, reliability cannot depend on guesswork. It needs a documented, tested, and continuously improved operating model.
An SRE Playbook is a structured guide that helps engineering and operations teams respond to incidents in a consistent, measurable, and reliable way.
It explains what to do when something breaks, who should take ownership, how to investigate the issue, when to escalate, and how to communicate progress.
A strong SRE Playbook usually includes service ownership, alerts, severity levels, diagnostic steps, rollback actions, escalation contacts, customer communication rules, and postmortem guidelines.
Google’s SRE approach connects reliability with engineering discipline. SRE teams are responsible for areas such as availability, latency, performance, efficiency, change management, monitoring, emergency response, and capacity planning.
Incidents create pressure. Dashboards turn red, users complain, leaders ask for updates, and engineers must act quickly without making the situation worse.
A documented SRE Playbook removes confusion during these moments. It gives every responder a shared operating model.
With a playbook, teams can:
The playbook does not replace engineering judgment. It supports judgment with structure, clarity, and repeatable action.
An effective SRE Playbook should be practical enough for real incidents and detailed enough for new team members to follow.
| Element | Purpose | Example |
|---|---|---|
| Service Overview | Explains what the service does | Payment API supports customer checkout |
| Ownership | Defines who owns the service | Primary on-call, backup on-call, service owner |
| SLIs and SLOs | Measures reliability expectations | 99.9% successful checkout transactions |
| Alerts | Defines when action is required | Error rate above 5% for 5 minutes |
| Diagnostics | Guides investigation | Logs, metrics, traces, deployment history |
| Mitigation Steps | Restores service quickly | Rollback, scale, restart, failover |
| Communication Plan | Keeps stakeholders informed | Status updates every 15 or 30 minutes |
| Postmortem Template | Captures learning | Timeline, root cause, action items |
This structure gives teams a reusable SRE playbook example that can be customized for APIs, cloud platforms, databases, Kubernetes clusters, customer applications, and internal systems.
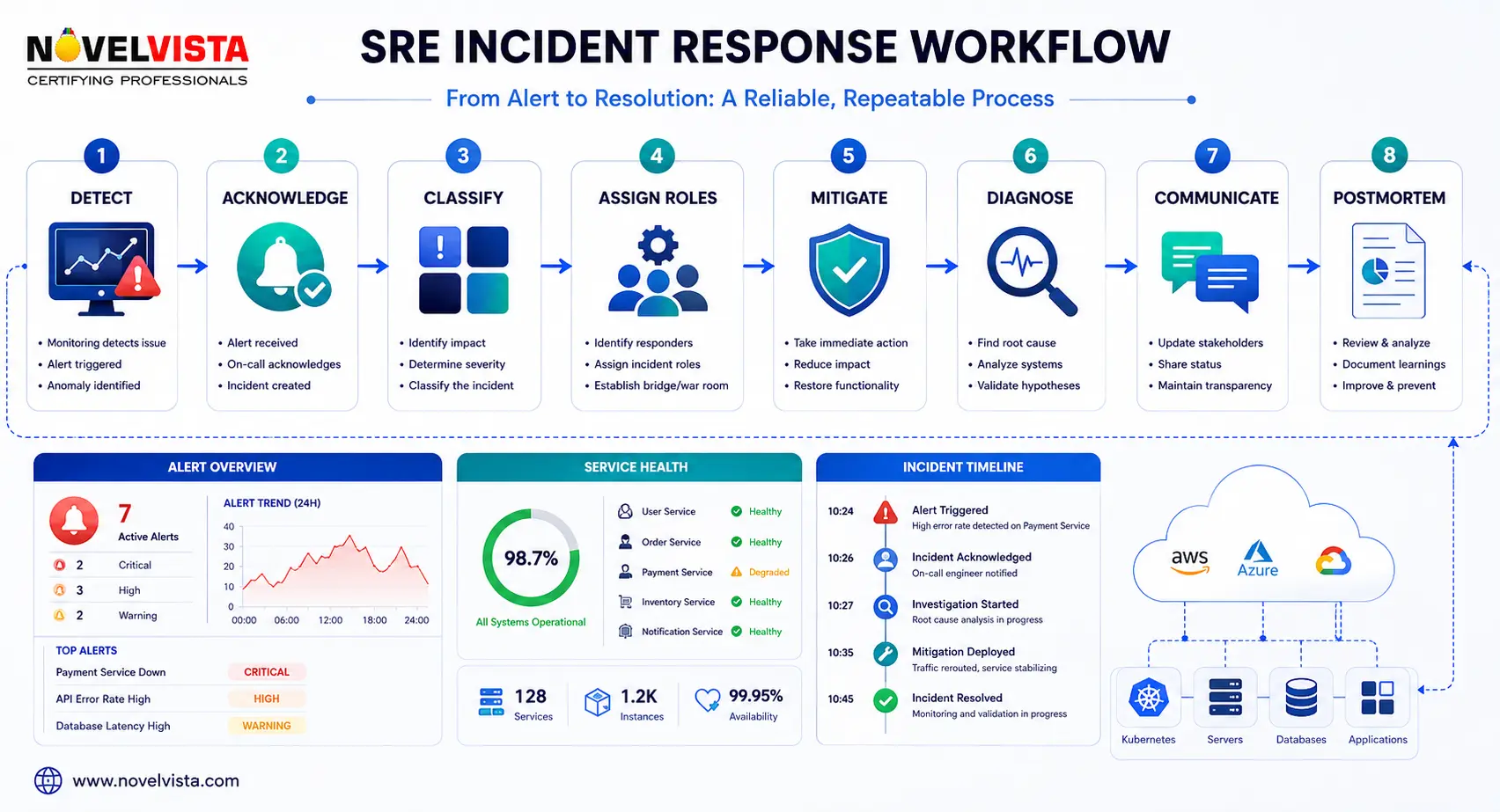
This SRE Playbook Step By Step workflow gives teams a practical way to move from alert to recovery without unnecessary chaos.
Detection should begin with user-impacting signals. Focus on availability, latency, error rate, traffic, saturation, failed transactions, and customer-facing symptoms.
The on-call engineer should acknowledge the alert quickly and confirm whether the issue is real, recurring, or false positive.
Severity should be based on customer impact, affected services, revenue risk, data risk, and availability of workarounds.
Define clear roles such as incident commander, technical lead, communications owner, and scribe. Small teams may combine roles, but ownership must remain clear.
Mitigation comes before perfect root-cause analysis. Teams may roll back a release, disable a feature flag, scale resources, restart workers, or route traffic to a healthy region.
Check recent changes, logs, traces, dashboards, infrastructure events, dependency health, and deployment timelines. Avoid assumption-led troubleshooting.
Internal updates should include impact, current status, owner, action taken, next step, and next update time. External communication should be calm, accurate, and customer-focused.
Confirm recovery using synthetic tests, real user monitoring, transaction checks, error-rate dashboards, and support signals.
The final step is a blameless review. Teams should document what happened, why it happened, how it was detected, how recovery happened, and what must change.
This SRE Playbook Step By Step approach helps responders move with confidence instead of improvising under pressure.
Role clarity is one of the fastest ways to improve incident response. When everyone knows their lane, the team avoids duplication, confusion, and silent assumptions.
| Role | Responsibility |
|---|---|
| Incident Commander | Owns the overall response, coordinates people, and makes priority decisions |
| Technical Lead | Investigates the technical issue and recommends mitigation steps |
| Communications Owner | Sends stakeholder, leadership, and customer updates |
| Scribe | Documents timeline, decisions, commands, and recovery actions |
| Service Owner | Provides deep application or platform context |
| Support Liaison | Shares customer impact signals from support channels |
For severe incidents, these roles should be assigned immediately after classification.
Severity levels create a common language for impact. They help teams decide how fast to respond, who to involve, and how frequently to communicate.
| Severity | Impact | Response | Example |
|---|---|---|---|
| SEV-1 | Major customer or revenue impact | Immediate response with leadership visibility | Checkout unavailable globally |
| SEV-2 | Partial outage or major degradation | Urgent response with cross-team support | High latency in one business-critical region |
| SEV-3 | Limited customer or internal impact | Same-day investigation | Delayed background job processing |
| SEV-4 | Minor issue or improvement item | Planned resolution | Non-critical dashboard warning |
Escalation should be simple: primary on-call first, backup on-call next, service owner after that, and leadership when customer impact or business risk is high.
Here is a practical SRE playbook example for a high-latency API incident.
The alert fires when p95 latency crosses the defined threshold for five consecutive minutes and customer requests begin timing out.
This SRE playbook example should be updated after each incident because systems, dependencies, and failure patterns change over time.
An SRE Playbook becomes more effective when it is connected to measurable reliability outcomes.
| Metric | What It Measures | Why It Matters |
|---|---|---|
| MTTA | Mean time to acknowledge | Shows alert response speed |
| MTTR | Mean time to recover | Shows how quickly service is restored |
| Error Budget Burn | Reliability risk against SLO | Balances release speed and stability |
| Change Failure Rate | Incidents caused by releases | Improves deployment safety |
| Alert Noise Ratio | Useful alerts compared with noisy alerts | Reduces pager fatigue |
| Repeat Incident Rate | Recurring failures | Shows whether postmortems are effective |
Google’s SRE material includes dedicated topics around service level objectives, monitoring, alerting, emergency response, incident management, and postmortem culture. These are core foundations for building mature reliability practices.
Many teams write incident documents but still struggle when production systems fail. Usually, the problem is not documentation. It is lack of ownership, practice, or continuous improvement.
A good playbook should be short enough to use during incidents and detailed enough to guide meaningful action.
Start with one critical service. Do not attempt to document the entire technology estate in one sprint.
Use this minimum structure:
Then improve the document through game days, tabletop exercises, production incidents, and post-incident reviews.
For deeper context, read NovelVista’s guide on SRE incident response and explore the SRE mindset guide to understand the cultural side of reliability.
This SRE Playbook Step By Step structure works best when it is treated as a living operational asset, not a one-time compliance document.
A strong SRE Playbook helps teams move from reactive firefighting to structured reliability engineering. It gives responders clarity, improves incident communication, reduces recovery time, and turns every failure into a learning opportunity.
The real value comes from practice. Build the playbook, test it, improve it, and keep it aligned with real production behavior. Reliability is not a document sitting in a shared folder. It is a working habit across people, process, and technology.
If you want to build practical skills in SLOs, SLIs, error budgets, incident response, monitoring, automation, and post-incident improvement, explore NovelVista’s SRE Foundation Training Certification. This course is designed for DevOps engineers, cloud engineers, system administrators, IT operations teams, and professionals who want to apply reliability engineering in real-world environments.
Author Details

Confused About Certification?
Get Free Consultation Call
Stay ahead of the curve by tapping into the latest emerging trends and transforming your subscription into a powerful resource. Maximize every feature, unlock exclusive benefits, and ensure you're always one step ahead in your journey to success.


