Category | AI And ML
Last Updated On 11/05/2026

India's AI hiring momentum is no longer theoretical: official government communication citing the Stanford AI Index 2025 says India leads the world in AI talent acquisition, with an annual AI hiring rate of about 33%. That is exactly why generative ai interview questions have become a serious preparation area for freshers, developers, data professionals, and cloud engineers aiming for roles in TCS, Infosys, Wipro, Accenture, Capgemini, EY, Deloitte, GCCs, and fast-growing Indian AI startups. If you are preparing for a GenAI role in 2026, this is the most comprehensive guide you will find — covering 85 questions across all difficulty levels.
In 2026, GenAI interviews are significantly harder than they were in 2023 or 2024. Earlier, many interviews focused only on basic AI, machine learning, neural networks, and ChatGPT-style awareness. Today, interviewers expect candidates to understand Generative AI, Large Language Models (LLMs), Prompt Engineering, Fine-Tuning, RAG, agentic AI, multimodal models, vector search, hallucination control, model evaluation, security, and responsible AI. A candidate who only knows definitions will struggle; companies now test whether you can design real-world GenAI systems. You may also want to explore our broader AI interview questions guide as a complementary resource.
This guide is written for freshers preparing for entry-level AI roles, experienced professionals with 2–7 years of experience moving into GenAI roles, and GenAI engineers or developers preparing for senior-level technical interviews. It covers 85 generative ai interview questions and answers across beginner, intermediate, advanced, architecture, ethics, and quick-revision levels. Each answer is designed to be educational, interview-ready, and practical enough for Indian hiring scenarios.
You will start with a quick refresher on how GenAI works, then move into generative ai interview questions for freshers, experienced professionals, GenAI engineers, and advanced architects. The article also covers prompt engineering, fine-tuning, RAG pipelines, Generative Adversarial Networks (GANs), Diffusion Models, Transformers, Embeddings, Vector Database concepts, ethics, preparation strategy, certification guidance, and FAQs. Bookmark this guide, because it is designed as a complete interview companion.
Generative AI is a branch of artificial intelligence that creates new content such as text, code, images, audio, video, synthetic data, designs, and conversations by learning patterns from existing data. Unlike traditional AI systems that usually classify, predict, or recommend, GenAI models generate outputs that resemble human-created content. This is why tools such as ChatGPT, GitHub Copilot, Midjourney, DALL-E, Stable Diffusion, Gemini, Claude, and enterprise copilots have become so important in business workflows. To understand this more deeply, read our blog on what is the main goal of Generative AI.
For interviews, GenAI matters because companies are no longer hiring only data scientists who can train models from scratch. They are hiring professionals who can use pretrained models, design prompts, build RAG applications, integrate APIs, manage vector databases, evaluate model outputs, and deploy AI-powered applications securely. In Indian service and consulting companies, GenAI skills are now relevant for banking, healthcare, ITSM, cybersecurity, education, insurance, cloud operations, customer support, and enterprise automation.
Generative AI models are trained on large datasets using unsupervised or self-supervised learning. For example, a language model learns from massive text corpora by predicting missing words, next tokens, or relationships between pieces of text. An image model learns visual patterns from image-caption datasets. The model does not memorize every sentence or image in a simple database-like way; instead, it learns statistical relationships, patterns, structures, and representations that help it generate new outputs.
Neural networks power most modern GenAI systems. These networks contain layers of mathematical functions with parameters and weights. During training, the model makes predictions, calculates errors, and updates weights through optimization methods such as gradient descent. Over billions of examples, the model learns that certain words, pixels, code structures, or semantic concepts are related. This is why an LLM can complete a sentence, write code, summarize a policy document, or answer a customer support question.
Inference is the generation phase. When a user provides a prompt, the model converts the input into tokens, processes those tokens through learned parameters, and predicts the most likely next tokens. This continues until the answer is complete. The model is not thinking like a human; it is generating based on learned probability patterns. However, with good architecture, high-quality training, retrieval augmentation, and prompt design, the result can feel highly intelligent and useful in professional applications.
Traditional AI and Generative AI both use data and algorithms, but their goals are different. Traditional AI usually focuses on prediction, classification, optimization, and decision support, while Generative AI focuses on creating new content. In interviews, this difference is important because it helps you explain why GenAI requires different skills such as prompt design, hallucination handling, model evaluation, safety controls, and output validation.
| Aspect | Traditional AI | Generative AI |
|---|---|---|
| Purpose | Predicts, classifies, recommends, or detects patterns | Creates new text, images, code, audio, video, or synthetic data |
| Output Type | Labels, scores, categories, forecasts, decisions | Natural language answers, generated images, code, summaries, designs |
| Training Approach | Often supervised learning with labeled datasets | Often self-supervised, unsupervised, or large-scale pretraining |
| Examples | Fraud detection, churn prediction, spam filtering, demand forecasting | Chatbots, image generators, code assistants, document summarizers |
| Creativity | Limited; mainly selects or predicts from learned categories | Higher; can generate novel combinations from learned patterns |
| Data Requirements | Usually task-specific and structured/labeled data. | Very large datasets, often unstructured text, image, audio, or code data |
This section is ideal for freshers preparing for generative ai interview questions for entry-level AI, data, cloud, or software roles. Freshers are usually tested on concepts such as GenAI basics, tokens, neural networks, LLMs, GANs, Transformers, datasets, and model limitations. The best way to answer basic questions is to start with a simple definition, explain how the concept works, and add a practical example.
Q1: What is Generative AI and how is it different from discriminative AI?
A: Generative AI is a type of artificial intelligence that creates new content by learning patterns from existing data. It can generate text, images, music, code, summaries, and designs. Discriminative AI focuses on identifying or classifying data, such as detecting whether an email is spam or predicting whether a customer will churn. Generative models learn the underlying distribution of data so they can produce new examples, while discriminative models learn boundaries between classes. For example, a discriminative model may identify whether a photo contains a cat, but a generative model can create a new cat image.
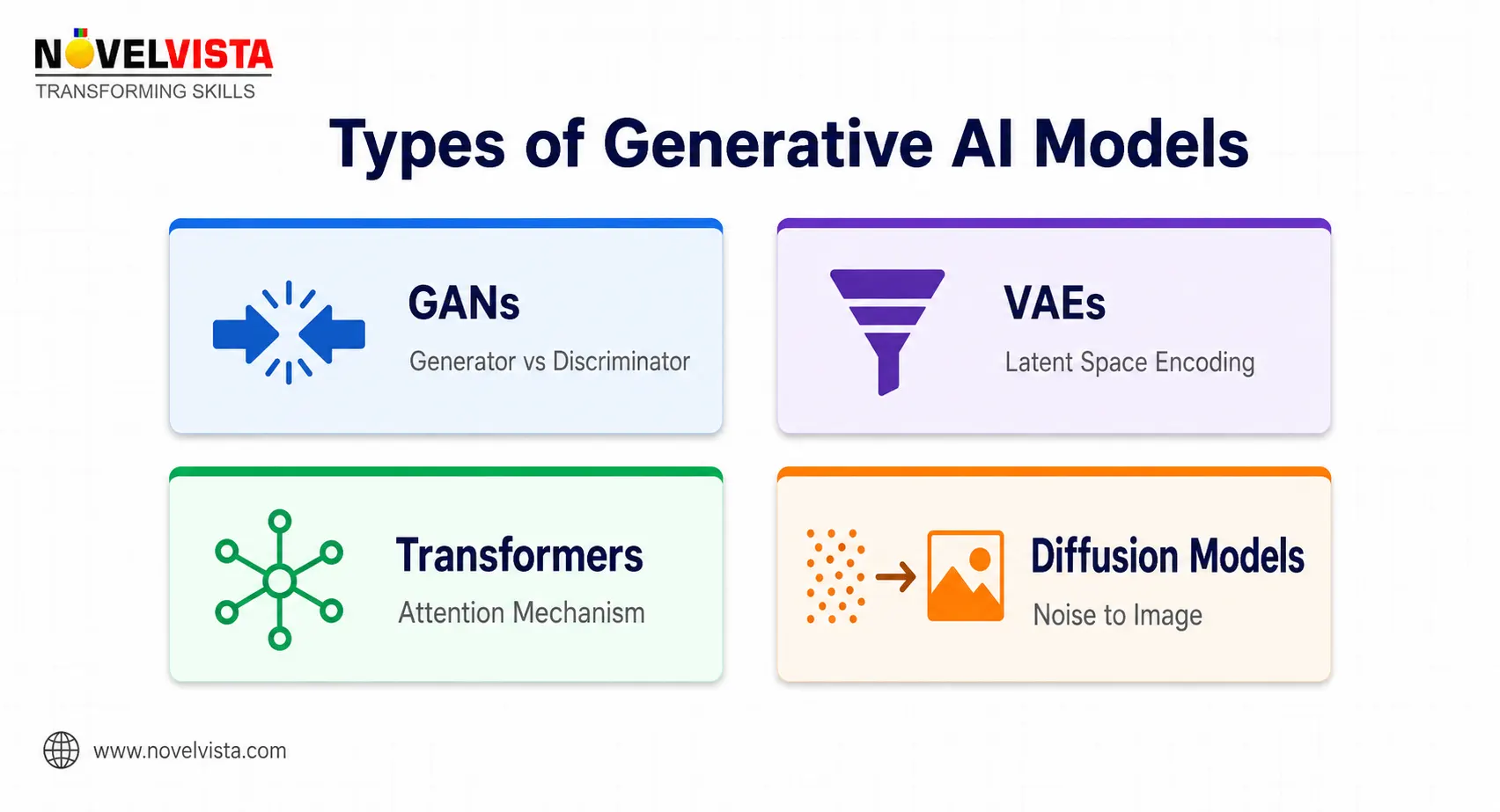
Q2: What are the main types of generative AI models?
A: The main types of generative AI models include GANs, VAEs, Transformer-based models, diffusion models, and autoregressive models. GANs generate realistic outputs using a competition between two networks: a generator and a discriminator. VAEs learn compressed representations of data and generate new samples from that learned space. Transformer-based models power many modern language applications. Diffusion models generate images by gradually removing noise from random inputs.
Q3: What is a neural network and why is it important in generative AI?
A: A neural network is a machine learning model inspired by the structure of the human brain, using connected layers of artificial neurons to learn patterns from data. In generative AI, neural networks are important because they can learn complex relationships in text, images, audio, and code. During training, the network adjusts internal weights based on errors, gradually improving its ability to generate realistic outputs.
Q4: What is a training dataset and why does its quality matter in generative AI?
A: A training dataset is the collection of examples used to teach a generative AI model how language, images, code, or other data patterns work. Dataset quality matters because the model learns from whatever it is exposed to. If the dataset contains biased, outdated, incorrect, toxic, or low-quality content, the model may produce unreliable outputs. In professional environments, dataset quality directly affects accuracy, trust, compliance, and business risk.
Q5: What are tokens in the context of large language models?
A: Tokens are the smaller units of text that Large Language Models process, such as words, word fragments, punctuation marks, or symbols. An LLM does not directly read text exactly like humans do; it first breaks input into tokens using a tokenizer. Tokens affect cost and context window limits because most LLM APIs charge or restrict usage based on token count.
The GenAI model landscape is broad, and interviewers often test whether you understand which model type fits which problem. GANs are strong for synthetic media, VAEs are useful for latent representations, Transformers dominate language and code, and Diffusion Models are widely used for image generation.
Generative Adversarial Networks (GANs) use two neural networks: a generator that creates fake data and a discriminator that evaluates whether the data looks real. Through competition, the generator improves until its outputs become difficult to distinguish from real samples.
VAEs, or Variational Autoencoders, encode input data into a compressed latent space and then decode it back into generated output. They are more stable than GANs and mathematically interpretable.
Transformer-based models use attention mechanisms to understand relationships between tokens in a sequence. They power LLMs such as GPT-style models and are highly effective for text generation, summarization, translation, and code generation.
Diffusion models generate data by starting with random noise and gradually denoising it into a meaningful output. They are widely used in image generation because they produce high-quality and diverse results.
Q6: How does a GAN work? What are the generator and discriminator?
A: A GAN works through competition between two neural networks: the generator and the discriminator. The generator creates fake samples while the discriminator tries to distinguish fake from real. Over time, the generator improves by learning how to fool the discriminator. This adversarial process continues until the generated samples become realistic.
Q7: What is the difference between a VAE and a GAN?
A: A VAE learns to compress input data into a latent representation and then reconstruct or generate new samples from that latent space. It is generally more stable during training. A GAN uses adversarial training — GANs often produce sharper images but can be unstable and may suffer from mode collapse.
Q8: Why are Transformer models dominant in NLP and GenAI today?
A: Transformer models are dominant because they use attention mechanisms to understand relationships between tokens efficiently, even across long sequences. Unlike RNNs and LSTMs that processed text sequentially, Transformers can process tokens in parallel during training, enabling massive scale on large datasets.
Q9: What are diffusion models and how do they generate images?
A: Diffusion models create images by learning how to reverse a noise-adding process. During training, clean images are gradually corrupted with noise. The model learns how to remove that noise step by step. During generation, it starts with random noise and repeatedly denoises it until a realistic image appears, guided by a text prompt.
Q10: Which generative AI model would you use for text generation and why?
A: For text generation, I would use a Transformer-based large language model. Decoder-only Transformer architectures such as GPT-style models are specifically designed for predicting the next token based on previous tokens. They can generate emails, code, reports, summaries, and chatbot responses, making them ideal for most enterprise GenAI applications.
LLMs are central to most generative ai interview questions because they power chatbots, copilots, summarizers, and enterprise knowledge assistants.
Q11: What is a Large Language Model (LLM)?
A: A Large Language Model is a deep learning model trained on massive text datasets to understand and generate human-like language. It works by breaking text into tokens and predicting the next token based on context and learned patterns. LLMs can answer questions, summarize documents, generate code, translate languages, or draft emails.
Q12: How does GPT differ from BERT?
A: GPT is a decoder-only autoregressive model strong at text generation. BERT is an encoder-only model trained bidirectionally, making it strong for classification, search ranking, and question understanding. GPT is like a writer completing a paragraph; BERT is like a reader deeply understanding a sentence.
Q13: What is the role of attention mechanism in LLMs?
A: The attention mechanism helps an LLM decide which parts of the input are most relevant when generating or understanding text. Instead of treating every token equally, attention assigns importance scores to different tokens, enabling the model to capture long-range dependencies in language.
Q14: What is temperature in LLM inference and how does it affect output?
A: Temperature is an inference setting that controls the randomness or creativity of an LLM's output. A low temperature makes the model more deterministic and focused. A high temperature makes the model more creative and varied. Use low temperature for accuracy-critical tasks like legal summarization, and higher temperature for creative tasks like marketing copy.
Q15: What are the limitations of current Large Language Models?
A: Current LLMs have several limitations: hallucination, bias, limited context windows, high compute cost, lack of real-time knowledge without tools, and difficulty with consistent reasoning on complex tasks. Understanding these limitations is critical because companies must build guardrails, evaluations, and human review before deploying LLMs in production.
Experienced professionals are tested on implementation depth, not just conceptual knowledge. Interviewers expect you to explain how prompt engineering, RAG, fine-tuning, evaluation, safety, and deployment decisions work in real systems. These generative ai interview questions are especially relevant for GenAI developers, cloud engineers, backend engineers, data engineers, and solution architects.
Prompt Engineering is now a core GenAI skill because many enterprise applications depend on how effectively instructions are written, structured, tested, and protected. If you want structured, hands-on training in this area, NovelVista's Prompt Engineering Course is designed specifically for professionals building production GenAI systems.
Q16: What is prompt engineering and why is it critical in GenAI applications?
A: Prompt engineering is the process of designing, structuring, and refining inputs given to a generative AI model so that it produces accurate, relevant, safe, and useful outputs. It works by giving the model clear instructions, context, examples, constraints, output format requirements, and role-based behavior. Prompt engineering is critical because most teams use pretrained models through APIs rather than training from scratch. In production, prompts should be versioned, evaluated, monitored, and protected against injection.
Q17: What is the difference between zero-shot, one-shot, and few-shot prompting?
A: Zero-shot prompting provides only instructions with no examples. One-shot provides one example. Few-shot includes multiple examples so the model can learn the desired pattern from context. Few-shot is useful when output format, tone, or reasoning style must be consistent. The limitation is that examples consume context window space and may increase token cost.
Q18: What is chain-of-thought prompting and when should you use it?
A: Chain-of-thought prompting encourages a model to reason through a problem step by step before producing an answer. Use it for tasks involving logic, math, planning, or multi-step decision-making. Avoid it for simple tasks as it adds tokens and latency. Best practice is to combine it with validation rules for complex reasoning workflows.
Q19: How do you handle prompt injection attacks in production GenAI systems?
A: Prompt injection attacks occur when user or external content tries to override system instructions or bypass safety rules. To handle this: separate trusted system instructions from untrusted user or retrieved content, sanitize inputs, validate outputs, use allow-listed tools, apply least-privilege access, and log all injection attempts.
Q20: What are system prompts and how do they differ from user prompts?
A: A system prompt is a high-priority instruction that defines the model's role, rules, tone, boundaries, and behavior for an application. A user prompt is the request entered by the end user. System prompts are controlled by developers; user prompts are dynamic and potentially untrusted. System prompts should not be the only security layer as prompt injection may still attempt to bypass them.
Q21: How would you design a prompt for a customer service GenAI bot to minimize hallucinations?
A: Design the prompt to strictly ground answers in approved knowledge sources. The system prompt should define the role, supported topics, escalation rules, and output style, including a fallback message when the answer is not found in retrieved documents. Require citations, include retrieved knowledge snippets, and add post-generation checks for unsupported statements.
Fine-tuning is important when a base model needs to adapt to a specific domain, tone, instruction style, or task pattern. It differs from prompt engineering because it changes model behavior through additional training.
Q22: What is fine-tuning in the context of generative AI and when would you use it?
A: Fine-tuning means taking a pretrained model and training it further on a smaller, task-specific dataset so it performs better for a particular use case. Use it when prompt engineering alone does not produce consistent results, when output style must be highly standardized, or when domain-specific patterns repeat at scale.
Q23: What is the difference between fine-tuning and prompt engineering?
A: Fine-tuning changes model behavior through additional training. Prompt engineering changes behavior by modifying inputs at inference time — faster, cheaper, and easier to iterate. Best practice is to start with prompt engineering and RAG, then fine-tune only when there is a measurable business need.
Q24: What is LoRA (Low-Rank Adaptation) and why is it popular for fine-tuning LLMs?
A: LoRA is a parameter-efficient fine-tuning technique that updates a small number of additional trainable parameters instead of all model weights. It works by injecting low-rank matrices into specific model layers, enabling task-specific adaptation with much lower compute and memory requirements. This is popular because it reduces fine-tuning cost by up to 10x while achieving near full fine-tune quality.
Q25: What data do you need to fine-tune a generative AI model effectively?
A: You need high-quality, representative, task-specific data with clear input-output examples. Data should be cleaned, deduplicated, balanced, and reviewed for bias, toxicity, privacy risks, and outdated information. Start with smaller, high-quality datasets rather than large noisy datasets — fine-tuning success depends more on data quality than model size.
Q26: What are the risks of fine-tuning a model on low-quality or biased data?
A: Fine-tuning on poor data can cause the model to produce inaccurate, unfair, or unsafe outputs. If data contains factual errors, the model may learn and repeat them confidently. Biased training data leads to discriminatory responses. Another risk is catastrophic forgetting, where the model loses general capabilities after being trained too narrowly.
Q27: How do you evaluate whether a fine-tuned model is performing better than the base model?
A: Compare both models on a held-out test dataset reflecting real user scenarios. Evaluation should include task-specific metrics, human review, and production-relevant criteria. Automated metrics alone are not enough because GenAI outputs may be fluent but wrong. Deploy only if the fine-tuned model shows measurable improvement in business outcomes.
RAG has become one of the most important topics in generative ai interview questions because companies need GenAI systems that answer from current, private, and domain-specific knowledge.
Q28: What is RAG and why was it developed?
A: RAG, or Retrieval-Augmented Generation, combines information retrieval with language generation. It was developed to overcome LLM limitations — especially hallucination, outdated knowledge, and lack of access to private enterprise data. The user query retrieves relevant documents from a knowledge base, which are passed to the LLM as context to generate grounded answers.
Q29: How does RAG work — explain the retrieval and generation pipeline step by step?
A: Document ingestion → chunking → embedding each chunk → storing embeddings in a Vector Database such as Pinecone, FAISS, ChromaDB, or Weaviate → user query embedded → similarity search retrieves relevant chunks → chunks inserted into prompt → LLM generates grounded answer → post-processing adds citations and fallback messages.
Q30: What is a vector database and which ones are commonly used with RAG?
A: A vector database stores and searches high-dimensional embeddings by semantic similarity. Common options: Pinecone (managed, scalable), FAISS (fast, open-source), ChromaDB (developer-friendly), Weaviate (hybrid search + metadata filtering), Milvus, and Qdrant. They enable semantic search — finding relevant content by meaning, not just exact keyword match.
Q31: What is the difference between RAG and fine-tuning — when would you choose one over the other?
A: RAG gives a model access to external knowledge at inference time — ideal for factual accuracy over current or private documents. Fine-tuning changes model behavior through training — ideal for consistent style, format, or domain behavior. Best practice is combining both: fine-tune for behavior, use RAG for knowledge. Start with RAG as it is easier to update without retraining.
Q32: What are embeddings and how are they used in a RAG pipeline?
A: Embeddings are numerical vector representations capturing semantic meaning. In RAG, embeddings compare the meaning of user queries with document chunks — enabling retrieval of semantically relevant content even when exact words differ. For example, a query for leave carry forward rules can retrieve a document titled Annual leave balance transfer.
Q33: What are the main failure modes of a RAG system and how do you debug them?
A: RAG can fail at ingestion (poor chunking), embedding (domain mismatch), retrieval (irrelevant chunks returned), or generation (model ignores context or hallucinates). Debug by inspecting retrieved chunks for sample queries, measuring recall@k and answer faithfulness, then applying metadata filtering, hybrid search, reranking, or better chunking strategies.
Q34: How would you evaluate the quality of a RAG system in production?
A: Evaluate using retrieval metrics (recall@k, precision@k, MRR), generation metrics (faithfulness, factual accuracy, citation correctness), and business KPIs (resolution rate, hallucination rate, user satisfaction, latency). Tools: RAGAS, TruLens, DeepEval. Track these continuously — production GenAI success depends on ongoing evaluation, not just successful demos.
Q35: What is hallucination in generative AI and why does it happen?
A: Hallucination occurs when a model produces confident but incorrect, unsupported, or fabricated information. It happens because LLMs generate text based on statistical likelihood, not guaranteed truth. The model may fill knowledge gaps with plausible-sounding content. Mitigation: RAG grounding, citation requirements, fallback responses, lower temperature, and human review for high-risk decisions.
Q36: How do you detect and reduce hallucinations in an LLM-based application?
A: Detect hallucinations by comparing outputs against retrieved sources, requiring citations, using schema validation for structured outputs, and adding post-generation checks. Reduce them using RAG, lower temperature, instruction hierarchy, domain-specific tools, and fallback behavior when evidence is missing. Track hallucination rate as a production KPI.
Q37: What types of bias can appear in generative AI models and where do they come from?
A: Bias can appear as social, cultural, gender, regional, language, professional, or historical bias, stemming from training data, fine-tuning data, human feedback, or evaluation datasets. For example, a model trained mostly on Western corporate writing may not handle Indian workplace communication well. Continuous monitoring, diverse datasets, fairness testing, and red teaming are required.
Q38: What is RLHF (Reinforcement Learning from Human Feedback) and how does it improve model safety?
A: RLHF is a training approach where human reviewers rank model responses by preference. A reward model is trained from these rankings and used to fine-tune the LLM to produce more helpful, harmless, and honest responses. For example, RLHF can teach a chatbot to refuse unsafe requests and avoid toxic language.
Q39: What is a content moderation layer and why is it important in GenAI products?
A: A content moderation layer checks user inputs and model outputs for harmful, restricted, or policy-violating content — detecting hate speech, data leakage, malware instructions, or regulated advice. Moderation can happen before the prompt reaches the model, after generation, or both. It protects users, brands, and compliance posture in any customer-facing GenAI product.
Q40: How would you explain AI safety concerns to a non-technical stakeholder?
A: Connect AI safety to business risk: incorrect outputs, data leakage, bias, and manipulation can create financial, legal, and reputational harm. Safety controls are like seatbelts — they do not slow the business; they make AI safe at enterprise scale. Key controls include approved data sources, access control, moderation, monitoring, human review, and regular audits.
This section is for senior engineers, AI architects, GenAI leads, MLOps engineers, and developers preparing for advanced generative ai interview questions. At this level, interviewers expect more than definitions — they want system designers who can explain trade-offs, failure modes, and production operations. Roles like SRE and DevOps are also integrating GenAI; our SRE interview questions guide covers how these roles are evolving alongside AI adoption.
Q41: Explain the training dynamics of a GAN — what is the minimax game and what makes it unstable?
A: A GAN is trained as a minimax game between a generator and discriminator. The generator minimizes the discriminator's ability to detect fake data while the discriminator maximizes classification accuracy. Instability arises because there is no fixed target — both networks change simultaneously. If the discriminator becomes too strong, the generator receives weak gradients. Wasserstein loss, gradient penalty, spectral normalization, and label smoothing can improve stability.
Q42: What is mode collapse in GANs and how do you prevent it?
A: Mode collapse occurs when the GAN generator produces limited output varieties instead of capturing the full data distribution. The generator discovers a narrow set of outputs that consistently fool the discriminator, reducing diversity. Prevention: minibatch discrimination, unrolled GANs, Wasserstein GANs, gradient penalties, diversity regularization, and careful monitoring of output diversity alongside quality.
Q43: What are the differences between DCGAN, StyleGAN, and CycleGAN?
A: DCGAN introduced convolutional principles for more stable image generation — the foundational GAN architecture. StyleGAN (NVIDIA) controls generation through style vectors at different layers, separating high-level features from fine texture details for high-quality face generation. CycleGAN enables image-to-image translation without paired training data — for example, converting horse images to zebra style. Each solves a different problem: generation quality, style control, or domain translation.
Q44: How do you evaluate the quality of GAN-generated images?
A: Use quantitative metrics alongside human evaluation. Inception Score measures recognizability and diversity. FID (Frechet Inception Distance) compares the distribution of generated images with real images in feature space — lower FID is better. However, FID is sensitive to sample size and preprocessing. Always combine FID with diversity checks, domain expert review, and downstream task validation.
Q45: In what real-world scenarios are GANs still preferred over diffusion models?
A: GANs are preferred when inference speed or real-time generation is critical. GANs generate in a single forward pass — making them suitable for real-time video enhancement, face animation, super-resolution, game asset generation, and edge devices. Diffusion models are preferred for highest-quality text-to-image generation. Architecture choice should be driven by product constraints: latency, hardware, quality, and regulatory risk.
Q46: What are the ethical concerns of GANs in the context of deepfakes and synthetic media?
A: GANs can generate realistic synthetic media including fake faces, manipulated videos, and deepfake content. These can be used for misinformation, fraud, identity theft, political manipulation, and harassment. Mitigation requires watermarking, provenance tracking, consent policies, detection tools, content moderation, and legal compliance. Organizations using GANs should adopt responsible AI governance before deployment, not after reputational damage occurs.
Q47: How would you design a production-ready GenAI application architecture end to end?
A: Layers needed: UI → API gateway → auth → orchestration → LLM → retrieval (RAG) → safety layer → observability → feedback loop. Include rate limiting, cost controls, prompt versioning, fallback models, caching, human escalation, and audit logs. RAG document ingestion needs chunking, embedding, metadata tagging, indexing, and re-indexing workflows. Treat GenAI applications as distributed systems with AI risk, not simple API wrappers.
Q48: What is LangChain and how does it simplify building LLM applications?
A: LangChain is an orchestration framework for building LLM applications with chains, agents, memory, retrievers, and tools. It simplifies connecting models with external data sources, vector databases, APIs, and workflows. The benefit is faster prototyping — but production teams must understand internals to debug latency, retrieval errors, and prompt behavior. LlamaIndex is preferred for data-centric RAG workflows.
Q49: What are AI agents and how do they differ from standard LLM inference?
A: AI agents add planning, tool use, memory, and action loops to standard LLM inference. A standard LLM call is single input to output. An agent iterates toward a goal — checking calendars, creating invites, and sending confirmations for a meeting booking request. Production agents must have strict tool permissions, step limits, human approval for risky actions, structured outputs, and complete observability.
Q50: How do you handle context window limitations in production LLM applications?
A: Solutions include chunking, summarization, retrieval, sliding windows, memory compression, query rewriting, and hierarchical context selection. Summarize conversation history periodically instead of sending the entire chat. Pass the smallest sufficient context, not the largest possible — context engineering is as important as prompt engineering.
Q51: What is quantization in the context of LLMs and why is it important for deployment?
A: Quantization reduces model weight precision (16-bit to 4-bit or 8-bit) to save memory and speed inference. Common techniques: GPTQ, AWQ, bitsandbytes. It makes large models deployable on limited hardware. Trade-off: aggressive quantization may reduce quality on complex tasks. Always evaluate quantized models task-by-task before production deployment.
Q52: How do you manage LLM costs at scale in a production environment?
A: Model routing (cheaper model for simple tasks), prompt compression, response caching, batching, retrieval optimization to reduce context size, and cost telemetry from day one. Track cost per user, per workflow, per token. Implement observability before scale — GenAI applications can look affordable in demos and become expensive at enterprise scale due to hidden spikes from chat history or agent loops.
Q53: What observability tools and techniques do you use to monitor a GenAI application in production?
A: Track traditional metrics (latency, error rate, throughput, cost) and AI-specific metrics (prompt version, hallucination rate, retrieval quality, answer faithfulness, moderation flags, fallback rate). Tools: LangSmith, Arize Phoenix, Weights and Biases, MLflow, TruLens, RAGAS, DeepEval, OpenTelemetry. For RAG: log retrieved chunks, metadata filters, and citations. For agents: log every tool call and decision step.
Q54: Explain the self-attention mechanism in Transformers — how does it work mathematically?
A: Self-attention projects each token into Query, Key, and Value vectors. Attention scores are computed as the scaled dot product of Queries and Keys, then softmax is applied to get attention weights. These weights combine the Value vectors to produce context-aware token representations. In decoder-only models like GPT, causal masking prevents tokens from attending to future tokens during generation. Attention scales quadratically with sequence length — FlashAttention addresses this.
Q55: What is the difference between encoder-only, decoder-only, and encoder-decoder Transformer architectures?
A: Encoder-only (BERT): reads input bidirectionally, strong for classification, search, entity recognition. Decoder-only (GPT): generates text autoregressively, strong for chat, code generation, completion. Encoder-decoder (T5): uses encoder to understand input and decoder to generate output, useful for translation and summarization. Choose architecture based on task type, not assumption that every problem needs a chat model.
Q56: What are positional encodings and why are they needed in Transformers?
A: Transformers process tokens in parallel and have no inherent sense of order. Positional encodings inject sequence position information so the model understands word order. The original Transformer used sinusoidal encodings; modern models use learned embeddings, rotary positional embeddings (RoPE), or relative position methods. Without positional encoding, The dog chased the cat and The cat chased the dog would look identical to the model.
Q57: What is multi-head attention and what advantage does it provide over single-head attention?
A: Multi-head attention runs several attention mechanisms in parallel, each with its own learned projections, then combines their outputs. Different heads capture different relationship types: one may track syntactic structure, another entity references, another long-range dependencies. Single-head attention has only one perspective, limiting representational richness. Multi-head attention works like a team of analysts reading the same document from different angles.
Q58: How are word embeddings different from contextual embeddings like those produced by BERT or GPT?
A: Word2Vec and GloVe assign one fixed vector per word regardless of context. BERT and GPT produce context-dependent vectors — bank gets a different embedding in financial vs. geographical sentences. Contextual embeddings are more powerful for search, classification, question answering, and RAG retrieval. Always use contextual or domain-tuned embeddings for enterprise semantic search where meaning and ambiguity matter.
Q59: What is the role of the feed-forward layer in a Transformer block?
A: The feed-forward layer applies nonlinear transformation to each token independently after attention has mixed cross-token information. It expands the hidden dimension, applies an activation function, then projects it back. Feed-forward layers contain a large portion of model parameters and are critical to model capability — they enrich token representations beyond what token-to-token attention alone provides.
Q60: What are the key architectural differences between GPT-4, LLaMA 2, and Mistral?
A: GPT-4 is a proprietary frontier model via API — strong general reasoning and instruction following but not open-weight. LLaMA 2 (Meta) is open-weight — enabling organizations to experiment, fine-tune, and deploy in controlled environments. Mistral is known for efficient open-weight architecture using grouped-query attention, delivering strong performance relative to size. Choose based on use case: regulated data and privacy needs → open models; ease of integration and breadth → proprietary APIs.

Here are 20 must-know generative ai interview questions and answers covering all difficulty levels — ideal for last-minute revision before your interview.
Q61: What is tokenization in GenAI and why does it matter?
A: Tokenization breaks text into smaller units (tokens) before an LLM processes it. Tokens may be words, subwords, numbers, or punctuation. It matters because the model generates tokens, not raw text. Tokenization affects context length, API pricing, response speed, and output quality. A long legal document may exceed token limits even if it looks manageable to a human.
Q62: What is the difference between parameters and hyperparameters in GenAI models?
A: Parameters are internal learned model weights updated during training. Hyperparameters are external settings chosen before training — learning rate, batch size, temperature, max tokens. Analogy: ingredients adjusted by tasting are parameters; oven temperature and cooking time are hyperparameters. Developers using APIs cannot change model parameters but can tune inference hyperparameters like temperature and max tokens.
Q63: What is overfitting in Generative AI?
A: Overfitting happens when a model learns training data too closely and fails to generalize to new inputs. A model fine-tuned on a small set of support emails may generate responses that look too similar to training examples. Overfitting also increases privacy risk if the model memorizes sensitive data. Mitigation: diverse data, validation sets, regularization, early stopping, and evaluation on unseen examples.
Q64: What is ChatGPT technically?
A: ChatGPT is a conversational AI application built on large language models that generate text responses based on user prompts and conversation context. It uses Transformer-based language modeling and instruction-following techniques. ChatGPT is not a search engine — it generates responses based on learned patterns and may use tools or retrieval depending on product configuration.
Q65: What is the difference between GPT and Gemini?
A: GPT models (OpenAI) are widely used for chat, coding, enterprise copilots, and API-based applications. Gemini models (Google) are deeply connected with Google's AI ecosystem, including multimodal capabilities and Google Cloud integrations. Model selection should be based on evaluation, security, latency, cost, and business requirements — not on brand alone.
Q66: What is multimodal AI in the context of Generative AI?
A: Multimodal AI systems process and generate across multiple data types — text, images, audio, video, and code. A multimodal model may inspect a screenshot of an error and generate troubleshooting steps. Real business workflows rarely contain only plain text, making multimodal capability increasingly important for enterprise GenAI products.
Q67: What is the CLIP model and why is it important?
A: CLIP (Contrastive Language-Image Pretraining) learns relationships between images and text by training on image-caption pairs. It maps images and text into a shared embedding space. CLIP enables image retrieval from natural language queries and guides text-to-image generation. Industry use cases include visual search, content moderation, image tagging, and ecommerce search.
Q68: What is knowledge distillation in GenAI?
A: Knowledge distillation trains a smaller student model to imitate a larger teacher model. The teacher generates outputs or probability distributions that train the student to perform similar tasks with fewer parameters. This reduces cost and latency while enabling deployment on limited infrastructure. The student may not fully match the teacher for complex tasks but is practical for most business use cases.
Q69: What is Constitutional AI?
A: Constitutional AI guides a model using a written set of principles — a constitution — to improve safety and helpfulness. Instead of relying on direct human feedback for every case, the model critiques and revises its outputs according to those principles. This reduces dependence on large volumes of human preference labeling while maintaining alignment with safety goals.
Q70: What is instruction tuning and why is it important?
A: Instruction tuning trains a language model on instruction-response pairs so it reliably follows user commands. A base language model predicts text but may not behave like a helpful assistant. Instruction tuning improves its ability to answer questions, summarize, classify, translate, and follow formatting requirements — critical for most business GenAI applications.
Q71: What are PEFT methods in Generative AI?
A: Parameter-Efficient Fine-Tuning (PEFT) adapts large models by training only a small subset of parameters. Popular methods: LoRA, QLoRA, adapters, and prefix tuning. These reduce GPU memory needs, training cost, and storage. A company can maintain separate LoRA adapters for finance, HR, and customer support tasks without storing multiple full models.
Q72: What is the difference between semantic search and keyword search?
A: Keyword search matches exact words or phrases — fast and transparent but misses synonyms. Semantic search retrieves by meaning using embeddings — better for natural language queries and paraphrasing. For example, a query for salary slip can retrieve a document titled pay statement. Most production systems use hybrid search combining both approaches.
Q73: What are AI orchestration frameworks?
A: AI orchestration frameworks connect LLMs with prompts, tools, retrievers, memory, APIs, databases, and workflows. Examples: LangChain, LlamaIndex, Semantic Kernel, Haystack. They simplify RAG pipelines, agent workflows, tool calling, and prompt templates. Real GenAI products require more than one model call — they need controlled, observable workflow integration.
Q74: What is Mixture of Experts (MoE) in LLM architecture?
A: MoE activates only a subset of expert subnetworks per token, increasing model capacity without proportional compute cost per inference. This allows large total parameter counts while controlling active compute. MoE introduces routing complexity, load balancing challenges, and deployment difficulty — but separates total capacity from active compute for better scaling efficiency.
Q75: What is speculative decoding and why is it useful?
A: Speculative decoding uses a small draft model to propose token candidates and a large model to verify them. Accepted tokens skip the large model's generation step, improving throughput without changing output quality. It is useful for high-throughput applications like chatbots, coding assistants, and customer support copilots where inference speed is as important as quality.
Q76: What is FlashAttention?
A: FlashAttention is an optimized attention algorithm that reduces memory reads and writes by computing attention in tiles, making Transformer training and inference faster and more memory-efficient. It is especially useful for long sequences and large context windows. FlashAttention does not change the conceptual behavior of attention — it optimizes how attention is computed at the hardware level.
Q77: What is KV cache in LLM inference?
A: KV cache stores previously computed Key and Value tensors to avoid recomputing attention over all previous tokens at each generation step. This significantly reduces inference latency for chat and completion tasks. However, KV cache consumes memory — especially for long contexts, large batch sizes, and multi-user serving. Production teams must carefully manage memory, batching, and context length.
Q78: What is model merging in Generative AI?
A: Model merging combines weights, adapters, or capabilities from multiple models without full retraining. Techniques include weight averaging, task arithmetic, and adapter merging. The trade-off is unpredictability — merged models may gain some capabilities but lose stability or safety alignment. Model merging should be treated as experimental unless validated rigorously on real production tasks.
Q79: What are agentic AI architectures?
A: Agentic AI architectures let LLMs plan tasks, call tools, use memory, observe results, and adapt their next actions. A typical architecture includes: user goal → planner → tool registry → execution loop → memory store → policy layer → monitoring. Failure modes: tool misuse, prompt injection through tool outputs, runaway loops, and high cost. Design agents like workflow automation with intelligence — not unrestricted autonomous systems.
Q80: How do you evaluate LLMs using benchmarks like MMLU, HellaSwag, and HumanEval?
A: MMLU tests broad knowledge and reasoning across academic and professional subjects. HellaSwag tests commonsense reasoning and sentence completion. HumanEval evaluates code generation. Benchmarks are useful for initial model comparison but insufficient for production decisions — a MMLU winner may still hallucinate in your domain. Use public benchmarks for screening, then run domain-specific evaluations with real prompts and success criteria.
Ethics questions are now standard in GenAI interviews because companies want candidates who understand risk, not just innovation. A confident answer should show that you can balance business value with responsible AI controls, especially for enterprise clients in banking, healthcare, insurance, education, HR, and government projects.
Q81: How do you ensure fairness in a generative AI model's outputs?
A: Ensuring fairness requires action across data, model design, evaluation, deployment, and monitoring. Audit training and fine-tuning data for representation gaps, stereotypes, and historical bias. Test outputs across demographic, regional, linguistic, and cultural variations — for example, test an Indian hiring assistant across names, colleges, cities, genders, and language backgrounds. Define fairness expectations in system prompts. Avoid fully automating high-risk decisions without human oversight. To explore this further, read our blog on fairness in AI products.
Q82: What does explainability mean in the context of generative AI and why is it hard to achieve?
A: Explainability means being able to understand, justify, or trace why a model produced a particular output. It is hard because LLMs use billions of parameters in complex statistical interactions — unlike decision trees where you can trace a clear path. Practical explainability comes from system design: RAG source attribution, citations, audit logs, confidence indicators, model cards, and evaluation reports.
Q83: What frameworks or regulations govern responsible AI use in enterprise settings?
A: EU AI Act: risk-based obligations with high-risk AI rules phased in across 2026–2027. ISO/IEC 42001: the world's first AI management system standard for governing AI risks and opportunities. India's IndiaAI Mission (March 2024): focuses on compute access, data quality, indigenous AI capabilities, startup support, and ethical AI development. In enterprise settings these translate into risk assessment, documentation, human oversight, vendor governance, and continuous monitoring.
Q84: How would you respond if a client asked you to build a GenAI system that could generate misleading content?
A: First clarify the client's real objective — sometimes they want persuasive content without intending deception. If so, redirect toward transparent marketing, compliant personalization, or clearly labeled synthetic media. If the intent is deliberately misleading — fake reviews, impersonation, fraud, political manipulation — decline, document the refusal, and propose compliant alternatives with fact-checking, disclosure labels, and human approval workflows. Our blog on the responsibility of developers using Generative AI covers this topic in more depth.
Q85: What steps would you take to audit a GenAI system for potential ethical risks before launch?
A: Risk classification and use-case assessment → data review (privacy, consent, bias, quality) → prompt testing (normal, edge cases, adversarial, demographic variations) → RAG accuracy check (document permissions, source quality, citation behavior) → security review (prompt injection, data leakage, access controls) → moderation validation → logging and incident response setup → documented approval criteria with named reviewers and sign-off process.
When answering ethics questions in interviews: identify the risk → explain business impact → propose a concrete control → mention governance or monitoring. Specific, structured answers build far more interviewer confidence than broad statements about doing AI responsibly.
To prepare for generative ai interview questions in 2026, focus on tools and skills that map directly to real GenAI implementation work.
1. Python (NumPy, Pandas, PyTorch/TensorFlow)
Python is the most important programming language for AI and machine learning. NumPy and Pandas help with data processing, while PyTorch and TensorFlow support model development. Even if you use APIs, Python helps you build evaluation scripts, data pipelines, and prototypes.
2. Hugging Face Transformers
Hugging Face provides models, tokenizers, datasets, and training utilities for modern NLP and GenAI. Widely used for experimenting with open-source models such as BERT, T5, LLaMA-family, and Mistral-family models.
3. LangChain / LlamaIndex
LangChain and LlamaIndex help build LLM applications connecting models with tools, data, memory, and retrieval systems. LangChain is useful for chains and agents; LlamaIndex is strong for data-centric RAG workflows.
4. OpenAI API / Anthropic Claude API
Modern GenAI developers should understand how to call hosted LLM APIs, structure prompts, manage tokens, handle streaming responses, and implement safety checks. Understand pricing, latency, rate limits, and data governance.
5. Vector Databases (Pinecone, ChromaDB, FAISS)
Essential for RAG and semantic search. Pinecone is managed and scalable, ChromaDB is developer-friendly, and FAISS is powerful for similarity search. Understand embeddings, indexing, metadata filtering, and retrieval evaluation.
6. Prompt Engineering Techniques
Includes zero-shot, few-shot, chain-of-thought, system prompts, structured outputs, role prompting, context grounding, and prompt injection defense. NovelVista's Prompt Engineering Course provides hands-on training across these techniques for professionals building real-world systems.
7. Fine-tuning (LoRA, QLoRA, PEFT)
Fine-tuning adapts models to specific tasks or domains. LoRA, QLoRA, and PEFT methods make customization more affordable by training fewer parameters. Know when fine-tuning is better than RAG and when it is unnecessary.
8. MLOps for GenAI (MLflow, Weights & Biases)
GenAI systems need experiment tracking, model versioning, evaluation, deployment, and monitoring. If you come from a cloud background, our AWS interview questions guide complements cloud-native GenAI deployment knowledge.
9. Evaluation Frameworks (RAGAS, TruLens, DeepEval)
Measure answer quality, faithfulness, relevance, hallucination rate, and retrieval performance. GenAI evaluation is harder than traditional accuracy scoring — combine automated metrics with human review.
10. Cloud AI Services (AWS Bedrock, Azure OpenAI, GCP Vertex AI)
Cloud AI services enable enterprises to deploy GenAI securely with managed infrastructure, model access, governance, and integration options. For Indian MNC and GCC roles, cloud knowledge is a strong differentiator.
| Week | Focus Area | Topics to Cover | Resources |
|---|---|---|---|
| Week 1 | GenAI Fundamentals | Neural networks, tokens, Transformers, LLMs, GANs, VAEs, diffusion models, basic NLP | Beginner AI/ML notes, Hugging Face course basics, official model documentation |
| Week 2 | Intermediate — RAG, Fine-Tuning, Prompt Engineering | Prompt patterns, RAG pipeline, embeddings, vector databases, LoRA, hallucination handling | LangChain docs, LlamaIndex docs, Pinecone/FAISS tutorials, RAG evaluation guides |
| Week 3 | Advanced Architecture + Tools | Self-attention, multi-head attention, quantization, agents, observability, cost optimization | Transformer papers, Hugging Face blogs, cloud AI docs, MLOps tools |
| Week 4 | Mock Interviews + Ethics + Revision | 85 Q&A revision, responsible AI, EU AI Act, ISO 42001, IndiaAI Mission, scenario practice. | Mock interviews, project portfolio, responsible AI frameworks, this guide |
Certifications matter in the Indian job market because recruiters need fast ways to shortlist candidates from a large talent pool. When many applicants claim AI awareness, a recognized certification signals structured learning, seriousness, and role readiness. AI-skilled professionals command a significant salary premium — making focused preparation more valuable for career growth.
NovelVista's Generative AI Certification is designed to map closely to the real interview topics covered in this guide. It helps learners understand GenAI fundamentals, prompt engineering, RAG, LLM applications, responsible AI, and practical implementation concepts. For professionals in cloud, DevOps, software development, data, or ITSM, this structured approach connects theory with workplace use cases.
The strongest preparation strategy is certification plus hands-on practice. Study this guide, build small projects, revise these generative ai interview questions, and complete a structured certification path — you can become interview-ready in 4–6 weeks.

FAQ 1: What are the most common generative ai interview questions asked in 2026?
A: The most common generative ai interview questions in 2026 cover LLMs, prompt engineering, RAG, fine-tuning, hallucination, embeddings, vector databases, Transformers, model evaluation, and responsible AI. Freshers are asked about basic GenAI concepts, tokens, neural networks, and model types. Experienced professionals face questions on RAG architecture, prompt injection, fine-tuning trade-offs, and production deployment. Senior engineers encounter questions on self-attention, quantization, agents, observability, and cost optimization.
FAQ 2: How should a fresher prepare for a generative ai interview with no prior experience?
A: Start with AI and machine learning basics, then learn GenAI concepts — tokens, LLMs, Transformers, GANs, diffusion models, prompts, and hallucinations. Build simple projects like a PDF chatbot, resume summarizer, or FAQ bot. Learn Python basics and understand how APIs work. Show strong fundamentals, curiosity, and hands-on practice. NovelVista's Generative AI Certification is a great starting point for freshers who want structured, guided preparation.
FAQ 3: What is the difference between GenAI and traditional AI interview questions?
A: Traditional AI interview questions focus on supervised learning, classification, regression, model metrics, feature engineering, and algorithms. GenAI interview questions focus on content generation, LLMs, prompts, RAG, embeddings, hallucination, fine-tuning, safety, and deployment. GenAI questions are more open-ended and system-design oriented — candidates must explain model behavior, user experience, trust, cost, latency, and governance.
FAQ 4: Is prompt engineering important for generative ai interview questions for experienced professionals?
A: Yes, prompt engineering is very important for experienced professionals — it is one of the most practical skills used in real GenAI projects. Companies want professionals who can design prompts producing accurate, safe, structured, and business-ready outputs. For experienced candidates, go beyond say write better prompts — explain prompt testing, versioning, evaluation, and production guardrails. Our Prompt Engineering Course covers all of these areas with hands-on exercises.
FAQ 5: How does a generative ai certification help in cracking interviews at top companies?
A: A generative ai certification gives candidates structured learning, credibility, and a clear roadmap. It is especially useful for professionals transitioning from software, cloud, DevOps, data analysis, testing, ITSM, or project management into GenAI roles. Combined with projects and strong interview preparation, certification improves confidence and profile strength. Explore NovelVista's Generative AI Certification Course to see how it maps to every topic covered in this guide.
This guide covered 85 generative ai interview questions across fresher, intermediate, advanced, quick-reference, and ethics levels. You learned how GenAI works, how LLMs generate outputs, how prompt engineering and fine-tuning differ, how RAG systems are designed, how GANs and diffusion models work, and how senior engineers think about architecture, deployment, cost, safety, and evaluation.
The GenAI job market in India is expanding quickly, and preparation is the real differentiator. Many candidates know the buzzwords, but interviewers reward professionals who can explain mechanisms, trade-offs, failure modes, and practical implementation. If you master these generative ai interview questions, you will be far better prepared for technical discussions at Indian IT companies, GCCs, startups, and consulting firms.
To build structured, job-ready expertise, explore NovelVista's Generative AI Certification Course. It provides guided learning, expert mentorship, and certification support that can help you connect interview concepts with real workplace applications. Combined with this guide, the Generative AI Certification can help you prepare confidently for GenAI roles in 4–6 weeks.
Whether you are a fresher from Pune, a cloud engineer in Hyderabad, a developer in Chennai, or a senior engineer in Bengaluru, your next GenAI role starts with the right preparation. Learn deeply, build practically, answer clearly, and walk into your interview with confidence.
Author Details

Confused About Certification?
Get Free Consultation Call
Stay ahead of the curve by tapping into the latest emerging trends and transforming your subscription into a powerful resource. Maximize every feature, unlock exclusive benefits, and ensure you're always one step ahead in your journey to success.


