Category | DevOps
Last Updated On 05/03/2026

Modern digital products are built to move fast, but they must also stay reliable. A feature that breaks user trust is no feature at all. Today, customer expectations are unforgiving and immediate.
A study by SDL found that 82% of customers expect brands to be available whenever needed, not optional, but always-on accessibility.Meanwhile, Emplifi reports that 70% of consumers will abandon a brand after just two negative experiences.
Speed alone is no longer enough. Reliability is the real competitive advantage.
And that is why organizations are adopting SRE culture, a discipline that ensures fast delivery and dependable systems, working hand-in-hand with DevOps.
Many companies already have CI/CD pipelines, monitoring tools, and automation in place. Yet they still face frequent outages, firefighting incidents, and delivery bottlenecks. The question is not whether teams can deploy fast — The question is whether they can deploy fast and stay reliable.
To answer that, we must understand what SRE culture really is and how it aligns with DevOps.
If you’re exploring SRE as a skill path, you may also like this: SRE Certification Path
SRE culture (Site Reliability Engineering culture) is a set of principles and practices designed to maintain service reliability while supporting rapid innovation. Originating at Google, SRE focuses on engineering-driven reliability, not just operations support.
Instead of manual fixing and reactive tasks, SRE applies software engineering practices to operational problems, including:
Where traditional IT models depended heavily on people handling incidents and changes manually, SRE culture enforces automation, instrumentation, and continuous improvement.
The philosophy is simple: If a human has to do it more than once, automate it.
And if a system breaks, the solution must make it stronger next time, not just restore it temporarily.
For a deeper breakdown of how SRE works in real environments, refer to this guide on the SRE Process.
Understanding SRE culture is not just a technology decision; it is a business decision. Modern platforms support millions of transactions, distributed systems, cloud deployments, microservices, and third-party dependencies. The complexity is too high to rely on reactive teams alone.
SRE culture brings stability to rapid innovation cycles by focusing on:
With SRE, resiliency becomes intentional, not accidental.
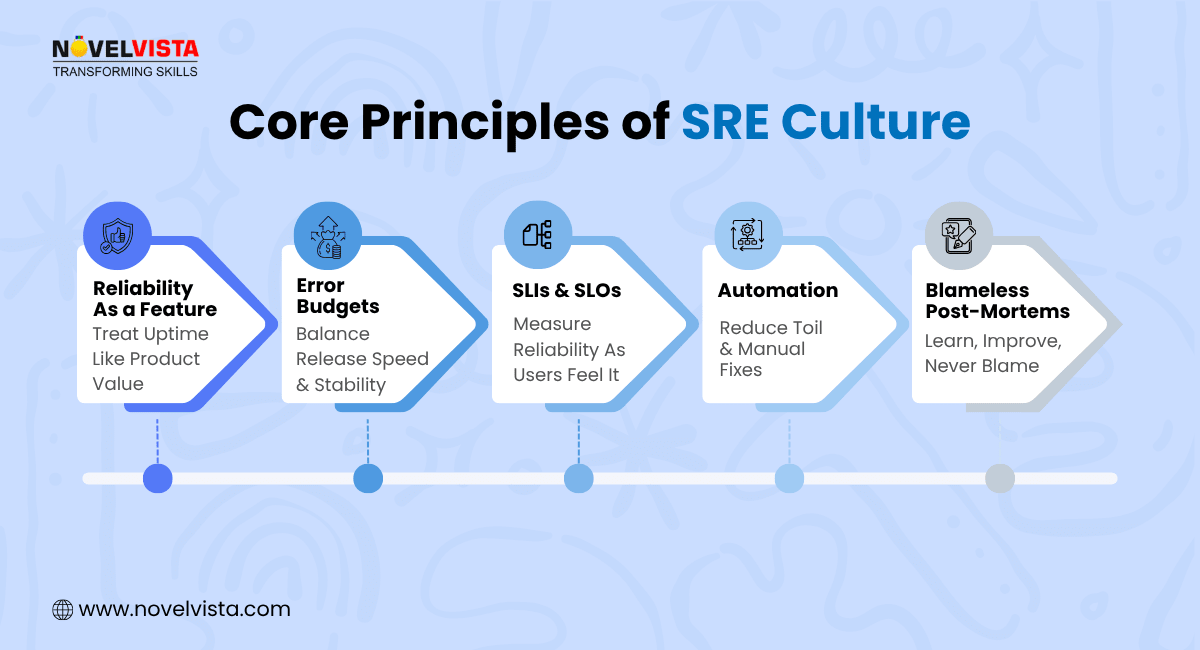
1. Reliability as a Feature
Just like performance or security, reliability is treated as a product capability that must be engineered, measured, and iterated.
2. Error Budgets
Instead of chasing zero failure, error budgets balance speed and safety. If applications consume their error budget, deployments pause and teams refocus on reliability.
3. SLIs and SLOs
Service Level Indicators (SLIs) and Service Level Objectives (SLOs) measure performance and set reliability standards from a user's perspective.
4. Automation and Toil Elimination
Manual and repetitive tasks are classified as toil. SRE teams aim to eliminate toil to improve productivity and system resilience.
5. Blameless Post-mortems
Failures become learning opportunities; individuals are not blamed. The system improves through knowledge, not fear.
If you're curious about roles and growth in this field, explore the SRE Jobs & Career Guide
Many people assume SRE replaces DevOps, but that is inaccurate. SRE is not a substitute; it is an implementation framework for DevOps reliability goals.
Key differences
Focus Area |
DevOps |
SRE |
Core Philosophy |
Collaboration & delivery speed |
Reliability engineering |
Goal |
Faster deployments |
Reliable and scalable systems |
Approach |
Culture & automation |
Engineering & service targets |
Measurement |
Deployment frequency, lead time |
SLIs, SLOs, error budgets |
Both share automation, collaboration, CI/CD, and monitoring practices, but SRE operationalizes DevOps reliability.
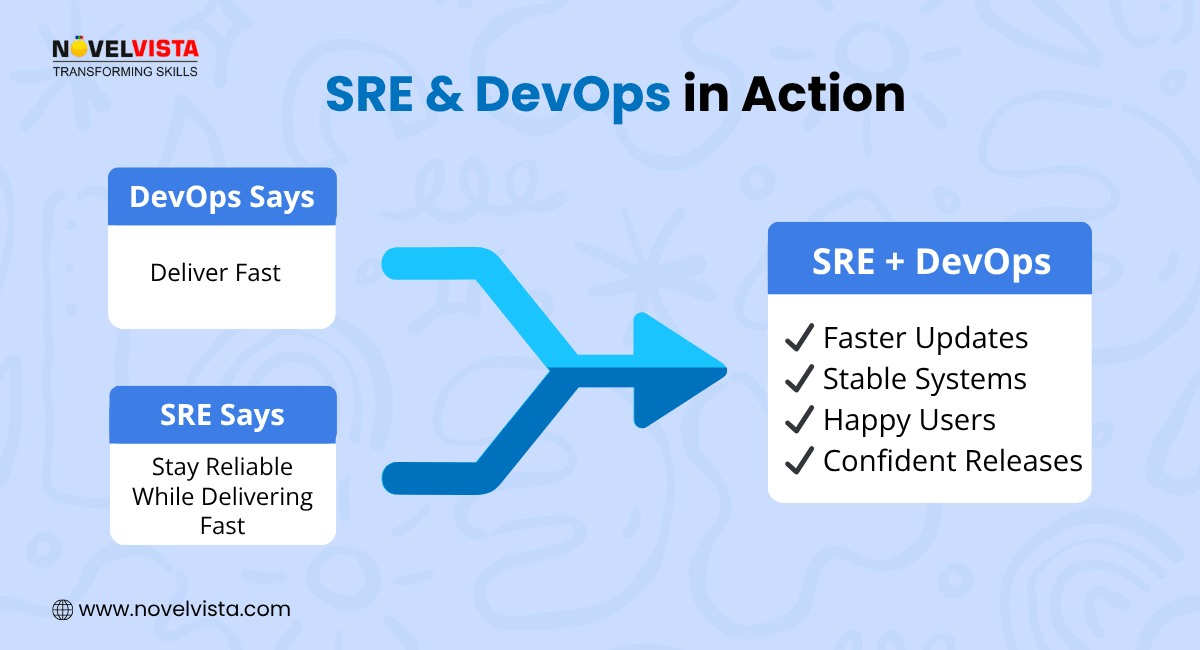
To explain the sre and devops culture relationship, think of DevOps as the roadmap and SRE as the engineering vehicle driving through it.
DevOps defines how teams collaborate, ship software, break silos, and automate workflows. SRE ensures those systems stay reliable, measurable, and scalable.
Connection Points
This explains the sre relation to devops culture, SRE adopts and enhances DevOps values with engineering rigor and measurable reliability goals.
Teams often ask: sre vs devops culture — which one to choose?
The answer is: you do not choose; you combine.
A good analogy:
DevOps says, “Move fast.”
SRE says, “Move fast, but do not break reliability.”
Common Challenges in Adopting SRE Culture
Implementing sre culture requires maturity and evolution. Common challenges include:
Effective SRE adoption requires leadership alignment, engineering commitment, and cultural patience.
What Google, Netflix, and Amazon expect from SREs
Master the exact skills and duties that define top reliability engineers.
To successfully embrace SRE culture, organizations should:
SRE is not a team; it is a philosophy. A small dedicated group may lead it, but the whole engineering ecosystem follows it.
As customer expectations rise and digital systems scale, reliability becomes non-negotiable. SRE culture is the natural evolution of DevOps, a structured, measurable, engineering-driven approach to reliability. Organizations that integrate sre culture with DevOps will ship faster, recover quicker, innovate confidently, and deliver consistent digital trust. In a world where users expect uninterrupted digital access and abandon brands after just two failures, resilient systems are not a luxury; they are a necessity. SRE culture and DevOps culture are not rivals; they are partners building the future of reliable digital delivery.

Step confidently into the future of engineering with in-demand SRE skills. Site Reliability Engineering is now a core capability for modern tech teams, not just a niche role. NovelVista offers two structured learning paths for real-world impact:
SRE Foundation Certification – Perfect for beginners or IT professionals transitioning into SRE. Build fundamentals in automation, SLIs/SLOs, error budgets, and incident response through guided labs and practical scenarios.
SRE Practitioner Certification – Designed for professionals ready to master advanced SRE practices, including observability, chaos engineering, and end-to-end reliability strategy—preparing you for senior SRE roles.
Author Details

Confused About Certification?
Get Free Consultation Call
Stay ahead of the curve by tapping into the latest emerging trends and transforming your subscription into a powerful resource. Maximize every feature, unlock exclusive benefits, and ensure you're always one step ahead in your journey to success.


