Category | DevOps
Last Updated On 27/02/2026

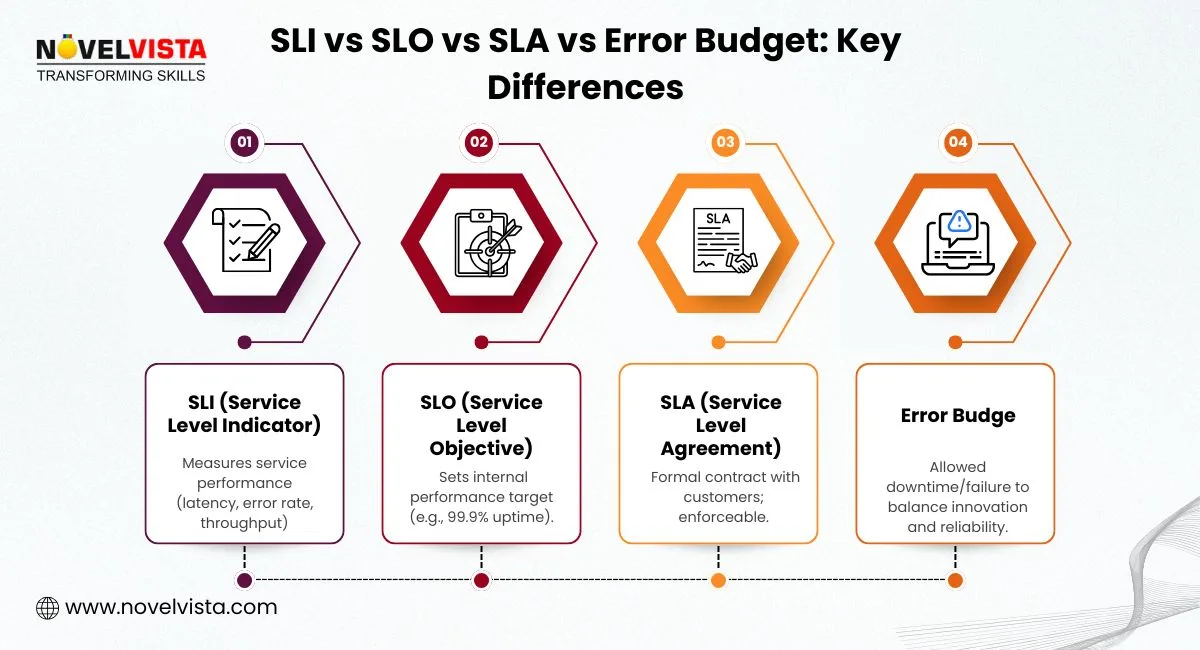
Understanding SLA vs SLO vs SLI is often confusing, yet these are the backbone of modern Site Reliability Engineering (SRE). Simply put: SLIs measure performance, SLOs set the target, and SLAs formalize commitments to customers. Error budgets act as a safety buffer, letting teams innovate while controlling risk.
For example, a streaming platform may track video start-up time (SLI), aim to have 99.9% of streams start within 2 seconds (SLO), guarantee this uptime in a contract (SLA), and use the allowable downtime as an error budget for testing new features.
This framework keeps services reliable, customer expectations clear, and engineering decisions grounded in data. This article will go through the difference between SLI vs SLO (SLO full form: Service Level Objective) vs SLA, what error budget is, how these 4 work together, and the best practices for the same. Let’s dive in!
A Service Level Indicator (SLI) is a measurable metric that reflects the health of a service. Unlike vague phrases like “the system is fast,” SLIs provide concrete, quantitative insights.
Some common SLIs include:
SLIs allow teams to identify trends, detect issues early, and make data-driven decisions. Think of SLIs like a car’s dashboard: speedometer, fuel gauge, and engine light show you what’s happening in real time.
A Service Level Objective (SLO) is the target set for an SLI over a defined period. It answers the question: “How good is good enough?”
Example: If your SLI measures latency, your SLO might state: “Average latency below 200ms for 95% of requests this month.”
SLOs are crucial because they provide internal benchmarks for reliability. If your SLO is met consistently, the system is performing well. If not, it signals the need for improvements.
Analogy: Think of SLOs as health targets, like maintaining a heart rate under 70 bpm during rest. The measurement (SLI) tells you your current state, and the target (SLO) guides behavior and decisions.
A Service Level Agreement (SLA) formalizes performance commitments with customers. It usually references the SLOs but adds accountability and sometimes penalties.
Example: A SaaS provider guarantees 99.9% uptime. If the provider fails, the SLA may require compensation, such as service credits.
SLAs ensure customers know what to expect and protect both parties legally. Internally, teams may focus on SLOs to stay on track, but the SLA defines the customer-facing promise.
Think of an SLA like a rental contract: it sets clear expectations for both landlord and tenant.
Component |
SLI |
SLO |
SLA |
Definition |
A metric that shows service performance. |
A target set for an SLI |
A contract with customers |
Purpose |
Measures service performance |
Sets the performance goal for SLIs |
Formal commitment to customers |
Focus |
Focus on service health |
Focus on the performance target |
Focus on customer commitment |
Examples |
Latency, error rate, throughput |
99.9% uptime, <200ms latency |
Uptime guarantees, support response time |
Audience |
Teams / Engineers |
Teams / Engineers |
Customers |
Measurement |
Real-time |
Monthly/Quarterly |
Monthly/Quarterly |
Legally Actionable |
No, it’s not legally actionable |
No, it’s not legally actionable |
Yes, it’s legally actionable |
Flexibility |
High – It can track many metrics. |
Medium – It can be adjusted for each service or time period. |
Low – Because of legal binding |
When to Use |
Use to monitor the system continuously. |
Use to guide internal reliability goals. |
Use for customer agreements and guarantees. |
Error Budget Relevance |
Provides data to set SLOs |
Defines allowed failure (error budget) |
Penalties apply if breached |
This table summarizes differences sla vs slo vs sli, but each concept plays a specific role in SRE. SLIs provide data, SLOs define goals, SLAs formalize commitments, and error budgets guide innovation without compromising reliability.
An error budget is the allowed level of service failure over a period. It lets teams balance reliability with the need to deploy new features.
For instance, if an SLO allows 0.1% downtime per month, that’s roughly 43 minutes of allowable failure. Teams can spend this budget on planned changes, A/B testing, or experiments.
Error budgets also improve collaboration: development teams can push updates without risking SLA violations, and operations teams know when to focus on stabilizing services. This creates a culture of measured risk-taking, where innovation and reliability coexist.
Error budgets are widely adopted in top tech organizations, including Google’s SRE teams, to balance innovation with service reliability. Applying error budgets effectively helps teams prioritize feature releases without risking SLA violations, following principles outlined in industry-standard SRE frameworks.
These four concepts are not isolated; they form a workflow that ensures reliable service delivery while allowing innovation. Here’s how they connect:
A cloud storage provider has:
If new updates increase downtime slightly, the error budget guides whether it’s acceptable or if mitigation is needed. This ensures both reliability and innovation.
Related: Organizational Impact of SRE
Before defining service level indicators, teams must understand the reliability metrics that actually describe system health. These measurements form the foundation for building meaningful SLIs, SLOs, and SLAs.
Together, these metrics provide measurable data that organizations convert into SLIs, which later define the service level objective and customer-facing commitments.
While SLI vs SLO vs SLA may sound technical, their real value lies in aligning engineering performance with business outcomes. Reliability metrics are not just operational numbers they directly influence revenue, customer trust, and brand reputation.
When implemented correctly, SLO vs SLA vs SLI transforms reliability from a technical concern into a strategic advantage, enabling faster delivery, better customer satisfaction, and measurable business value.
To get the most value from these metrics, follow these practical tips:
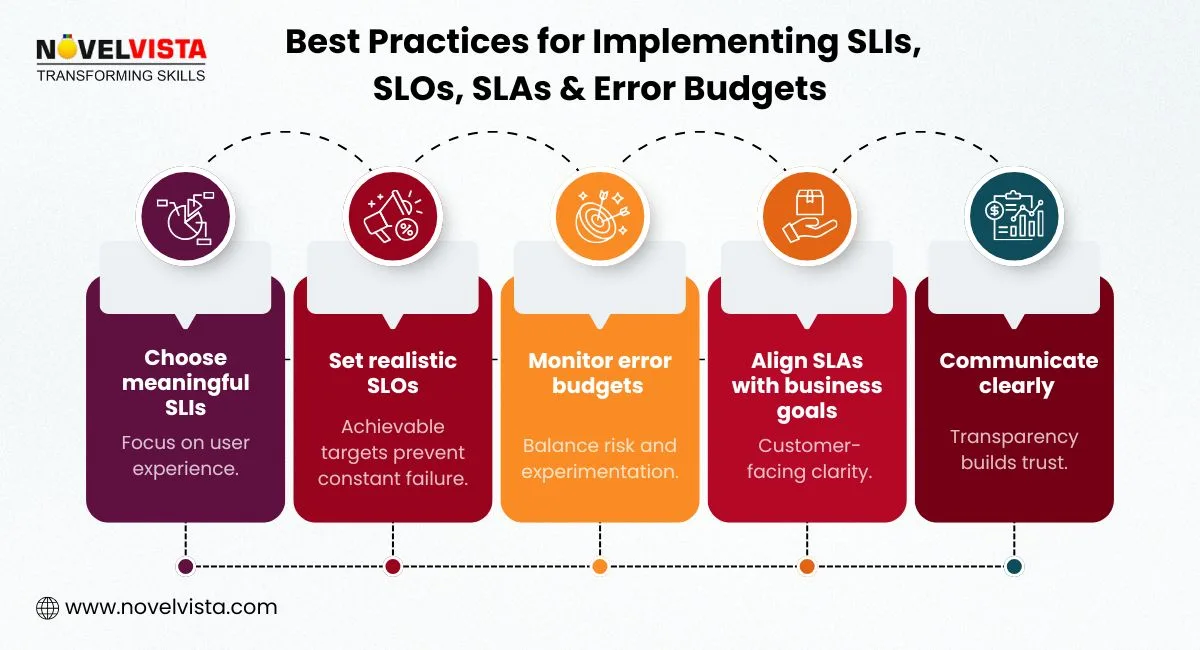
Even experienced teams can fall into pitfalls. Here’s how to avoid them:
By learning from these mistakes, teams can implement SRE metrics effectively, improving both reliability and innovation.
Also Read: SRE Roles and Responsibilities
The examples provided are based on observed patterns in real-world SRE implementations across e-commerce and streaming platforms. While specific numbers may vary by organization, these scenarios illustrate typical approaches to aligning SLIs, SLOs, SLAs, and error budgets.
Understanding SLA vs SLO vs SLI and how error budgets work together is crucial for modern Site Reliability Engineering. These concepts ensure reliable service delivery, align engineering goals with business needs, and create a safe space for innovation. By measuring the right things, setting achievable targets, and clearly communicating commitments, teams can prevent downtime, improve customer trust, and maintain operational efficiency.
Master the fundamentals of Site Reliability Engineering with NovelVista’s SRE Foundation Training. Learn how to define SLIs, set realistic SLOs, manage SLAs, and utilize error budgets to ensure reliable, high-performing systems. Gain hands-on knowledge to implement SRE practices in real-world projects and advance your career in modern IT operations. Enroll today and become a certified SRE professional.

Author Details

Confused About Certification?
Get Free Consultation Call
Stay ahead of the curve by tapping into the latest emerging trends and transforming your subscription into a powerful resource. Maximize every feature, unlock exclusive benefits, and ensure you're always one step ahead in your journey to success.


