Category | AI And ML
Last Updated On 29/12/2025

If generative AI is the rocket fueling digital transformation, then data is the oxygen keeping it alive. But here’s the twist: even in 2026, with petabytes of information flowing every second, data remains the biggest bottleneck in AI adoption.
Gartner reports that data availability and data quality are among the leading barriers to AI success, warning that organizations without AI-ready data risk abandoning a significant share of AI initiatives. Whereas Protiviti's AI Pulse study found that organizations confident in their data are 3× more likely to exceed AI ROI expectations, proving that data maturity directly correlates with AI impact
So the question is: If we have more data than ever, why is AI still struggling?
In this blog, we will see what challenge does generative AI face with respect to data, why it persists in 2026, and how businesses can overcome it.
Before we answer what challenge generative AI face with respect to data, we need to understand how these systems learn and operate.
Generative AI models consume:
Modern AI is not constrained by computing power. It is constrained by data readiness, data clarity, data formats, data governance, and ethical handling.
Powerful LLMs like GPT-5 only perform as well as the clean, consistent, complete, and trusted data they get.
A Simple, Step-by-Step Plan to
Transform Data into Reliable Insights.
There isn’t a single barrier; the challenge is multi-dimensional.
Data quality remains the biggest foundational issue. Duplicates, missing values, legacy systems, and weak metadata all undermine model accuracy. When evaluating what challenge generative AI faces with respect to data, poor quality consistently ranks first. Without automated cleaning and governance pipelines, generative AI quickly loses reliability and introduces business risk.
Bias in training data continues to cause skewed and unfair model outputs. Historical discrimination, subjective labeling, and poor demographic representation feed unintentional bias into AI systems. Even with diverse datasets, ongoing fairness checks are critical, as generative models can amplify subtle biases over time without proactive monitoring.
Strict global data regulations like GDPR, CCPA, India's DPDP Act, HIPAA, and the upcoming EU AI Act demand tight control over data access and consent. This makes privacy one of the biggest answers to what challenges generative AI faces with respect to data. Missing compliance controls risks fines, legal exposure, and loss of customer trust.
Strong governance ensures the right users and systems have access to sensitive data safely. Encryption, auditing, policy workflows, and zero-trust controls are now mandatory. Weak governance doesn't just reduce AI accuracy — it increases risk and slows adoption due to a lack of confidence and accountability in enterprise AI systems.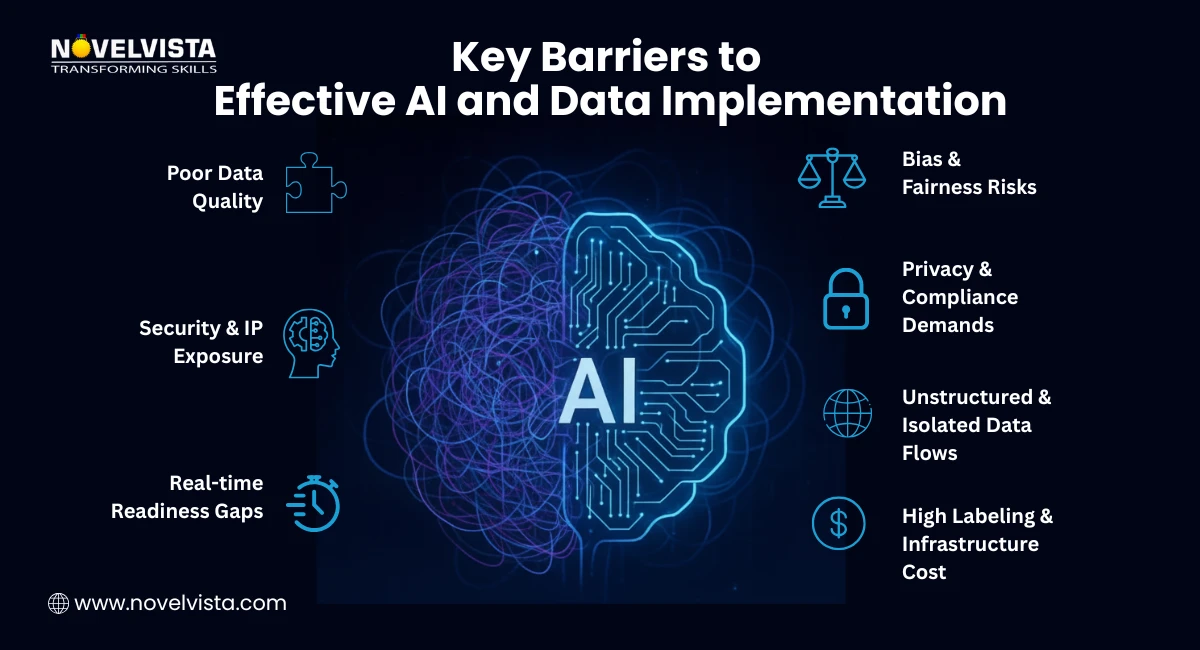
Over 80% of enterprise information sits unstructured across emails, drive folders, CRM notes, and chats. Many ask what type of data generative AI is most suitable for, and the most reliable results still come from structured and semi-structured data. The challenge lies in connecting and contextualizing dispersed unstructured data to extract business value.
For understanding what challenges does generative ai face with respect to data, you need to understand cost and complexity of data labeling. AI still needs human-verified training data, especially in regulated or specialized domains. Expert labeling and validation remain expensive and time-consuming. While synthetic data helps, poor annotation directly reduces model performance, making human oversight a critical part of high-quality AI pipelines.
Most legacy systems were built for batch processing, not real-time insight. Generative AI needs continuously updated data to avoid stale or incorrect outputs. Without streaming pipelines and low-latency infrastructure, models drift and lose effectiveness — weakening trust and decision confidence.
Data security challenges include accidental leaks to public models, shadow AI use by employees, and model extraction attacks. Enterprises now prioritize private LLMs, secure prompt gateways, and AI firewalls to protect confidential information and safeguard intellectual property.
Hallucinations happen when inputs are incomplete or inconsistent. Generative systems fill gaps confidently but incorrectly when the data context is missing. Retrieval-Augmented Generation (RAG) and grounding improve accuracy, but fundamentally, high-quality and complete data remains the best defense against hallucination risk.
Modern AI requires scalable data infrastructure — from lakehouses and vector databases to real-time pipelines and observability tools. IDC notes that organizations with mature data intelligence are far more likely to achieve successful AI outcomes. Legacy systems simply cannot support the growing data volume and velocity needed for generative AI at scale.
| Strategy | Benefit |
| Data governance frameworks | Controlled, auditable data |
| Quality automation | Clean, trusted data streams |
| Vector DB + RAG | Reduced hallucinations, context precision |
| Synthetic data | Safe augmentation for scarce datasets |
| Knowledge graphs | Better context understanding |
| Private LLMs | Security and compliance |
| Metadata & data catalogs | Single source of truth |
The future belongs to organizations that treat data as a product and AI as an ecosystem, not a standalone tool.
So, what challenge does generative AI face with respect to data?
The biggest barrier isn’t the model — it’s the data powering it.
Winning organizations aren’t asking,
“How do we use AI?”
They’re asking,
“How do we prepare and govern our data so AI can operate responsibly and at scale?”
Generative AI fails when data is fragmented, biased, unsecured, or poorly governed — not because the technology isn’t capable, but because the foundation isn't ready.
The new enterprise equation is clear:
Better data → Better AI → Better business outcomes.
AI transformation doesn’t start with the model.
It starts with the data.
Understanding why data holds back generative AI is a powerful first step, but growth really begins when you turn knowledge into hands-on capability. If you're planning to upskill and want structured, practical learning, from real use cases to prompt engineering, model workflows, and responsible AI practices, consider exploring the Generative AI Professional Training by NovelVista.
This program is designed to help you move from curiosity to confident execution, with guidance from industry experts and a curriculum aligned to real business needs.
Your journey from understanding AI to applying it starts here — one guided step at a time.
Author Details

Course Related To This blog
Generative AI Professional
Generative AI in Project Management
Generative AI in Risk & Compliance
Generative AI in Retail
Generative AI in Marketing
Generative AI in Finance and Banking
Generative AI for HR and L&D
Generative AI in Cybersecurity
Generative AI in Business
Generative AI in Software Development
Confused About Certification?
Get Free Consultation Call
Stay ahead of the curve by tapping into the latest emerging trends and transforming your subscription into a powerful resource. Maximize every feature, unlock exclusive benefits, and ensure you're always one step ahead in your journey to success.


