How often do you focus on adopting a new fashion trend and keeping up with it forever?
We bet that hasn’t happened even once. Because soon before the fashion trend fades, a
new one comes on board and you are all hyped about it. Isn’t that right?
The same thing happens with technology as well. Once a new one comes on board, that
becomes the most trending one! Such as Site Reliability Engineering (SRE), the much-
an adored the bridge between development and operations nowadays. By now, there must be a lot
of questions in your mind.
Some of them are maybe:
In this blog, we are going to answer all of the questions mentioned above. If you have any
more questions, you can always type it down in the comment section.
Do you know how much does a Site Reliability Engineer gets paid? It starts from $136,836
per year. Can you believe this?
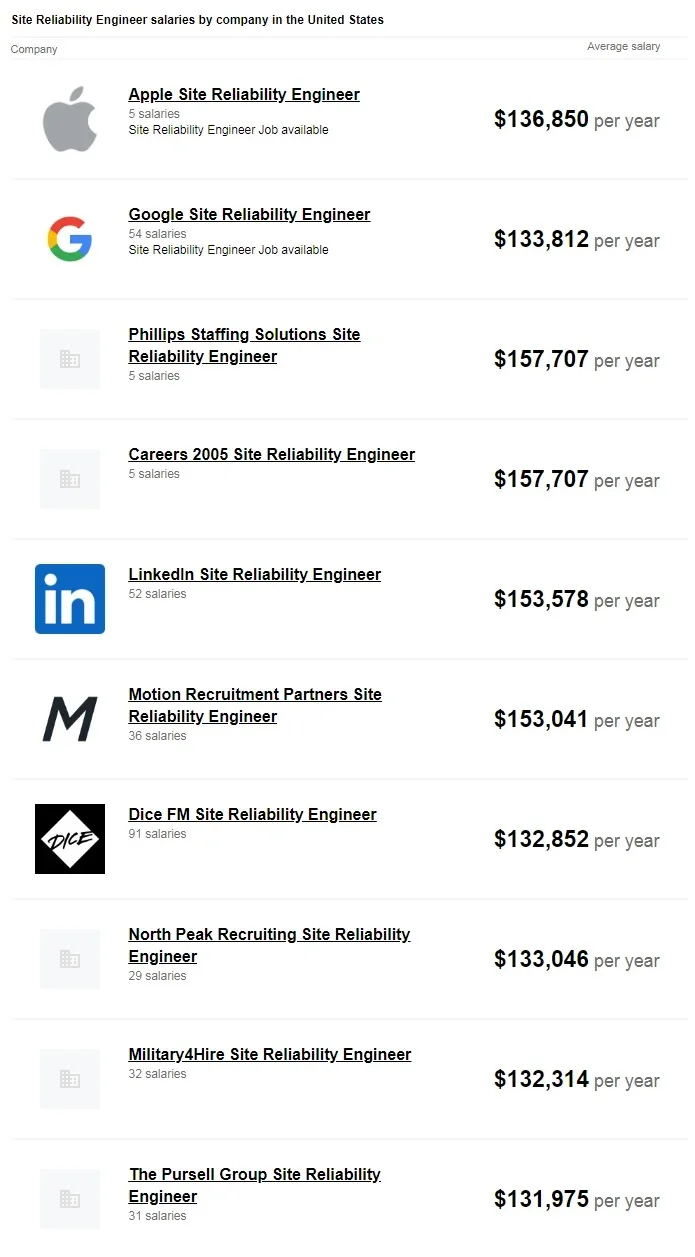
Source: Indeed
But why Site Reliability Engineers are in such high demand? Let’s see from the definition.
Platform Engineering has evolved as an essential discipline in the world of cloud-native systems. But how does it fit into the broader DevOps and SRE conversation? Platform engineering involves the creation and maintenance of platforms that enable developers to efficiently build, deploy, and scale applications. The key difference is that platform engineers create the "platform" or tools that both developers and operations teams use, allowing them to focus on higher-level tasks instead of ordinary infrastructure management.
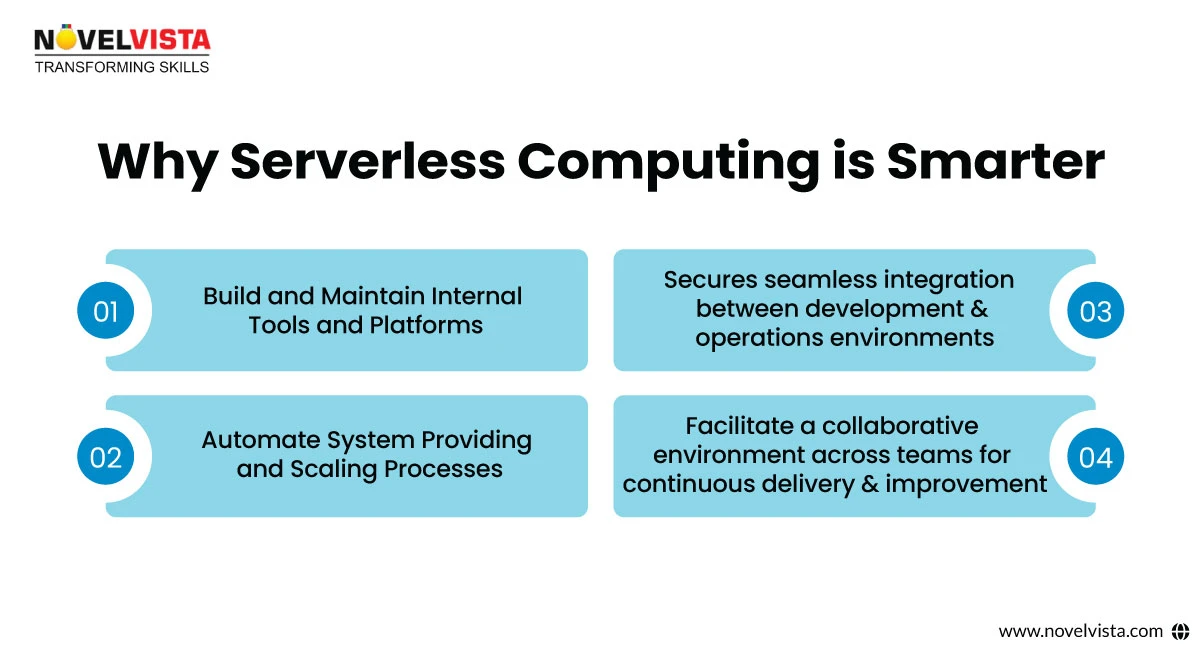
Key Responsibilities of Platform Engineers:
How It Complements or Differs from DevOps and SRE: Platform Engineering shares some common goals with DevOps and SRE, such as automation, collaboration, and system reliability. However, its primary focus is on developing reusable and flexible tools that support both teams. While DevOps focuses on the collaboration between developers and operations, and SRE makes sure of system reliability at scale, Platform Engineering is more about providing the internal architecture and tooling to support both these disciplines.
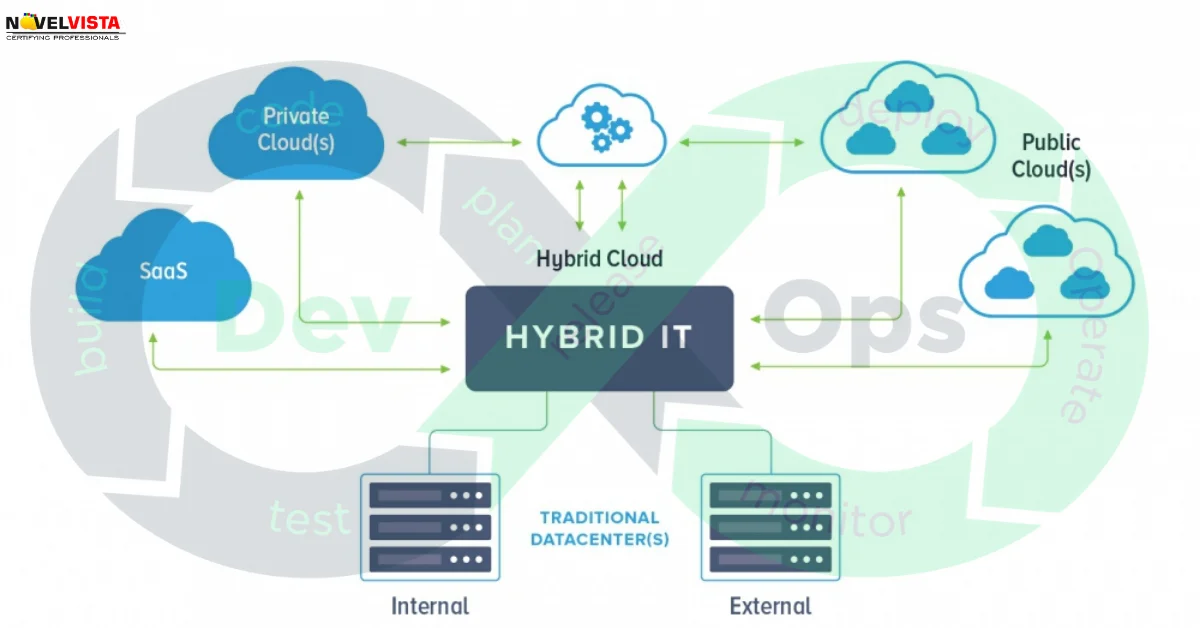
Site Reliability Engineering is basically creating a bridge between Development and
Operations departments. It is a discipline that incorporates aspects of software engineering
and applies them to infrastructure and operations problems. The main goals are to create
scalable and highly reliable software systems.
According to Benjamin Treynor , founder of Google's Site Reliability Team, SRE is "what
happens when a software engineer is tasked with what used to be called operations"
So, from where did the concept of SRE come from? To tell you that, we have to go back to
the year 2003. In that year, Benjamin Treynor was in charge of a production team whose
end goal was to make Google websites more available so that they are always able to
provide service.
Being a software engineer, Benjamin trained the way to work in a way the
way he could have worked if he were a Site Reliability Engineer. He tasked the team to
spend half of their time with the operations team so that they can understand the problem
and contribute to the development in a better way. The team Benjamin Treynor managed, is
Google’s SRE team now.
You might ask now, we already have DevOps dealing with both development and
operations. Why do we need SRE then? Is there any similarity between these two? Let’s
look into the principles and key aspects of both to find out!
From our previous blogs ITIL Vs DevOps , you all know about DevOps already. Right?
DevOps is basically a set of practices to build a culture of collaboration between the
development and operations teams.
The SRE principles are also aligned in a way so that all the above-mentioned points can be achieved. Let’s see how that can be done!
1. Reduce organizational silos:
SRE shares ownership with developers to create shared responsibility
SREs use the same tools that developers use, and vice versa
2. Accept failure as normal:
SREs embrace risk
SRE quantifies failure and availability in a prescriptive manner usingService Level Indicators and Service Level Objectives
SRE mandates blameless post mortems
3. Implement gradual changes:
SRE allows developers and product owners to function faster by reducing
the cost of failure
4. Leverage tooling and automation:
SREs have the charter to automate menial tasks away
5. Measure everything:
Hope we cleared the air of confusion here? Now, let’s see what a Site Reliability Engineer
has to be taken care of.
What is the role of an SRE?
We gave you a brief idea about the job role of Site Reliability Engineer.
Take a look at the following points, and you will find out the details:
Both DevOps and SRE depend on a variety of tools to simplify workflows, improve collaboration, and automate tasks that dull your energy. Below is a detailed comparison of the tools used in these workflows:
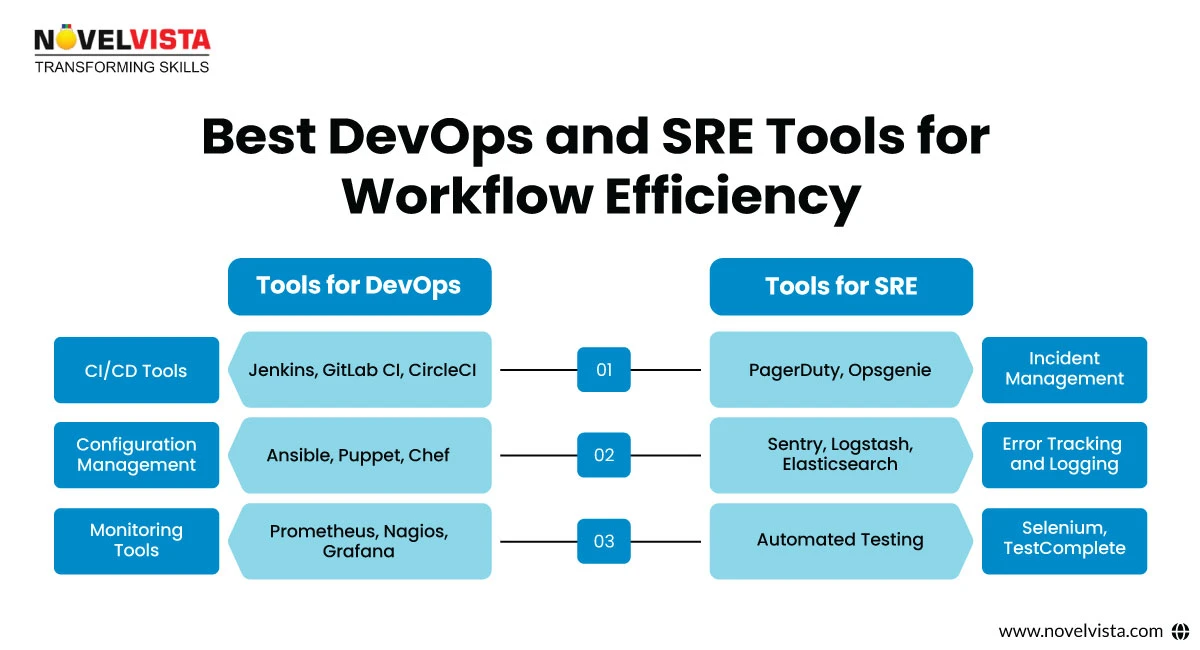
DevOps is ideal for organizations looking to improve collaboration and speed up software delivery.
By combining development and operations teams, DevOps minimises the outdated team structure that blocks agile development. Here’s why you might choose DevOps:
Best for: Teams focusing on delivering new features quickly and maintaining high collaboration between development and operations teams.
Understanding the SRE's meaning compared to DevOps' emphasis on speed can help organizations decide the right approach.
While DevOps focuses on collaboration, SRE adds another layer of dependability and scalability, making it a great choice for larger, more complex systems that require high uptime. Here’s why you might prefer SRE:
Best for: Organizations with large-scale, mission-important systems where uptime and reliability are of the highest priority.
If your organization is already using DevOps and looking to shift to SRE, here’s how to make the shift:
While both DevOps and SRE aim to improve efficiency and system dependability, there are a few common challenges:

Whether you’re considering using DevOps, SRE, or Platform Engineering, it’s important to understand the distinctions and similarities between these methodologies. DevOps is perfect for fostering collaboration and speeding up software delivery, while SRE ensures system reliability and scalability. Platform Engineering, on the other hand, empowers teams by creating reusable platforms that support both DevOps and SRE goals.
If you’re interested in mastering the difference between SRE and DevOps and improving your skills, check out the Site Reliability Engineering (SRE) Foundation course. Understand the variations of SRE implementation and equip yourself with the tools to elevate your systems and infrastructure.
Ready to dive deeper into SRE and DevOps? Explore the Future of SRE and learn how SRE Teams Are Using AIOps to take their workflows to the next level. Start learning today with NovelVista!
Master the principles of Site Reliability Engineering and become a certified expert.